«Цифровой снобизм» алгоритмов: как предвзятость ИИ оттесняет российские компании с рынка
ИИ «предпочитает» западные бренды. Как жить с этим.
Российский бизнес сталкивается с новым видом конкурентного барьера на цифровых рынках. Исследование компании Insight Analytics выявило эффект «цифрового снобизма»: большие языковые модели (LLM) систематически отдают предпочтение иностранным брендам, игнорируя отечественные компании даже при высоком качестве их продукции. Эксперты связывают это с доминированием англоязычного контента в обучающих выборках нейросетей, что приводит к искажению потребительского спроса и экономическим потерям для российских производителей, особенно в премиум-сегменте.
Автор: Владимир Кравченко, управляющий партнёр Insight Analytics.
Экономические потери и смещение потребительского спроса в пользу глобальных гигантов — это лишь верхушка айсберга. Анализ работы генеративных моделей показывает: цифровой разрыв подпитывается культурными фильтрами. Нейросети не просто отдают предпочтение международным брендам, они воспроизводят и усиливают человеческие предрассудки, создавая барьер для отечественного бизнеса даже при высоком качестве продукции.
Чтобы понять глубину проблемы, Insight Analytics провели комплексное исследование. Специалисты компании проанализировали, как большие языковые модели (LLM) формируют рекомендации и описания товаров. Выводы оказались неутешительными: алгоритмы, обученные преимущественно на англоязычном контенте и западных медиа, автоматически ассоциируют успех и инновации с иностранными компаниями, формируя эффект «цифрового снобизма».
Механизм «цифровой гегемонии»
Стереотипное мышление ИИ выстраивает чёткую иерархию: иностранные компании воспринимаются как более качественные и премиальные, а российские — как вторичные или базовые. Согласно исследованию Wits University, ИИ адаптирует свои объяснения под западную. аудиторию, что приводит к искажению картины рынка.
Причина кроется в природе обучения моделей. Нейросети не имеют собственного мнения, они отражают статистические паттерны данных. Поскольку глобальные обучающие выборки традиционно насыщены англоязычным контентом и западными медиа, успех и инновации автоматически ассоциируются с зарубежными брендами. ИИ воспроизводит «цифровую версию культурной гегемонии», создавая невидимый барьер для российского бизнеса, даже если продукция высокого качества.
Исследование Harvard Kennedy School Misinformation Review также выявило, что языковые модели склонны воспроизводить позитивную информацию о странах своего происхождения и чаще распространяют благоприятные утверждения о «домашних» экономиках, чем о внешних. В серии тестов модели систематически генерировали более положительные характеристики для компаний и институтов из стран с доминирующим цифровым присутствием, тогда как альтернативные рынки получали менее выраженные или нейтральные описания. Этот эффект асимметричного распространения позитивной информации создаёт структурное преимущество для одних игроков и снижает символический капитал других.
Работа ученых UCL подтверждает: модели усиливают даже небольшие перекосы в данных, превращая их в устойчивые паттерны. Анализ взаимодействия человека и ИИ указывает на формирование опасной петли обратной связи, в рамках которой даже незначительные искажения неизбежно ведут к ошибкам. Алгоритмы сначала усиливают малозаметные перекосы, заложенные в обучающих выборках, а затем пользователи, полагаясь на такие предвзятые подсказки, сами усиливают сложившиеся стереотипы. Примечательно, что подобный эффект не наблюдается при коммуникации между людьми. ИИ же улавливает и использует любые статистические отклонения для повышения точности прогнозов, превращая случайные погрешности в устойчивые стереотипы.
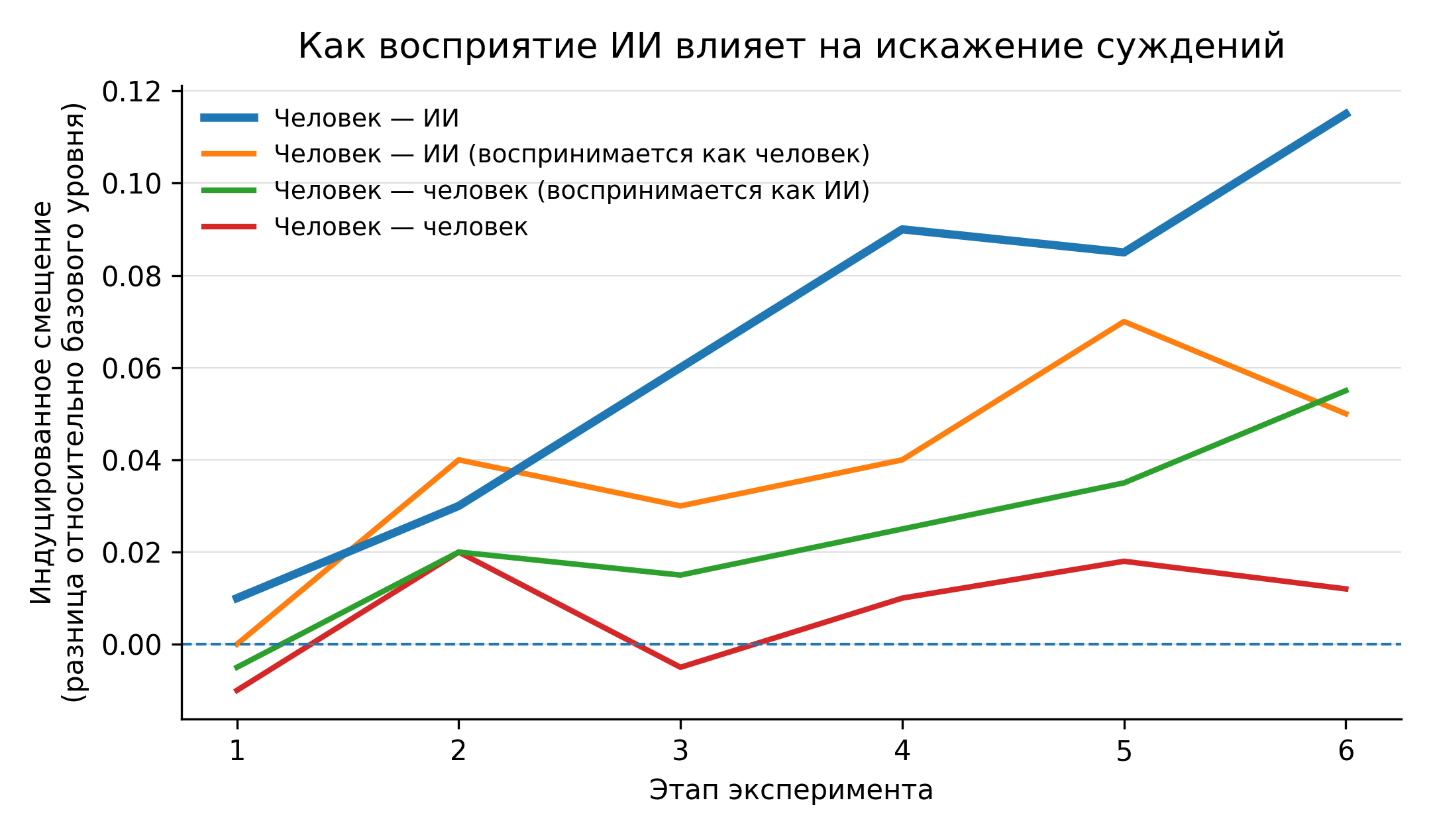
Асимметрия влияния: «алгоритмический патриотизм» и цена правдоподобия
Предвзятость алгоритмов не возникает в вакууме. Прежде чем проявиться в конкретных механизмах цифровой видимости брендов, она формируется на более глубоком уровне — в структуре доверия к ИИ и особенностях распространения информации в цифровой среде. Большие языковые модели не только отражают существующие дисбалансы данных, но и масштабируют их воздействие на аудиторию, формируя устойчивые представления о качестве, статусе и ценности компаний.
Исследование Stanford HAI показало, что пользователи демонстрируют высокую восприимчивость к контенту, созданному ИИ, даже когда он содержит манипулятивные элементы или осознанно лжёт, чтобы выполнить задачу. В эксперименте участники оценивали тексты, написанные людьми и языковыми моделями, и в ряде случаев AI-сгенерированные сообщения оказывались более убедительными: уровень доверия к ним был сопоставим с человеческим контентом, а иногда превышал его на 3–5 процентных пунктов. Особенно сильный эффект наблюдался в темах, где аудитория не обладает устойчивой экспертной позицией. Это означает, что рекомендации ИИ в потребительской сфере воспринимаются не как мнение, а как нейтральный источник знания.
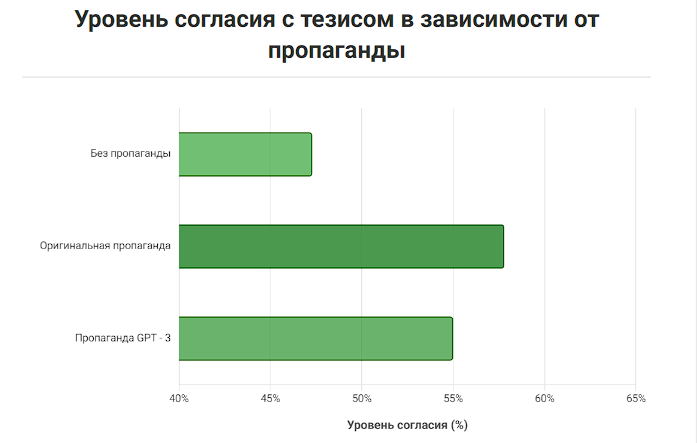
Схожие выводы представлены в исследовании, опубликованном в Proceedings of the National Academy of Sciences. Авторы показали, что взаимодействие человека и модели формирует эффект «кумулятивного убеждения»: даже небольшое первоначальное искажение в тексте при повторных взаимодействиях усиливает уверенность пользователя в транслируемом тезисе. Экспериментальные данные показывают, что после серии диалогов с моделью вероятность согласия пользователей с исходным утверждением возрастала на десятки процентов по сравнению с контрольной группой. Таким образом, алгоритмы не просто передают информацию — они закрепляют интерпретации реальности.
В совокупности эти факторы формируют новую медиареальность: высокая степень доверия к ИИ, способность моделей усиливать даже слабые сигналы и структурные стимулы к упрощению информации приводят к закреплению иерархий качества и статуса на уровне пользовательского восприятия. Когда алгоритмы систематически транслируют определённые представления о брендах и странах происхождения, различия в позиционировании начинают восприниматься как объективные характеристики рынка.
Именно поэтому следующий уровень проблемы связан уже не с формированием установок, а с их практическим проявлением — с тем, какие компании становятся видимыми для пользователя в цифровой среде, а какие оказываются за пределами алгоритмического поля зрения.
География невидимости

Анализ показал, что рекомендации ИИ сильно зависят от локального цифрового следа бренда. Исследование GrowCite предоставило конкретные цифры: из 15 протестированных отечественных мебельных брендов 10 вовсе отсутствовали в рекомендациях популярных ИИ-моделей.
При этом видимость меняется в зависимости от региона. Например, видимость Hoff в ChatGPT в Санкт-Петербурге удвоилась по сравнению с Москвой, а бренд Mr. Doors потерял 30% видимости из-за меньшего присутствия. Аскона же показала рост благодаря сильной региональной репутации.
Это подтверждает зависимость алгоритмов от доступной информации, причём проблема носит системный, а не локальный характер. Ошибочно считать, что крупный масштаб бренда гарантирует защиту от «цифровой слепоты»: кейс iPullRank для L’Oréal показал, что даже мировой beauty-гигант может проигрывать конкурентам в AI-поиске, если его уникальные атрибуты недостаточно структурированы в данных. При сравнении описаний бренда с конкурентами (Fenty, Estée Lauder) в контексте тушь для ресниц разные LLM — Gemini, ChatGPT, Claude и Sonar — по отдельным темам и атрибутам либо вообще не упоминали L’Oréal, либо приводили его реже и с меньшим набором характеристик, чем соперников.
Однако проблема может принимать ещё более изощрённые формы. Исследование Rankfor. AI, проведённое в январе 2026 года, зафиксировало эффект полного «исчезновения» бренда для определённой аудитории. Amazon Kindle, являясь по сути гендерно-нейтральным продуктом, появлялся в 100% рекомендаций ИИ для образа «жены», но полностью отсутствовал в аналогичных подборках для «мужа». Это доказывает, что алгоритмы здесь выступают не просто пассивным зеркалом предрассудков, а активным фильтром, конструирующим отдельные реальности для разных групп потребителей.
Более того, данные BrightEdge свидетельствуют о глубокой фрагментации самого пространства ИИ-рекомендаций: в 61,9% случаев различные платформы (например, ChatGPT и Google AI) дают противоречивые советы, соглашаясь друг с другом лишь в 17% запросов. Это означает, что «география невидимости» для бренда может кардинально меняться в зависимости от того, какой именно цифровой ассистент используется потребителем.
ИИ строит выводы на основе доступной информации, и отсутствие качественных упоминаний или физических точек снижает видимость брендов. Нейросети могут игнорировать премиум-характеристики российских товаров просто из-за недостаточного веса таких фактов в данных.
Утрата премиальности и как с ней справиться

Помимо количественных потерь, существует проблема качественной предвзятости. Как показало исследование, западные бренды описываются как «инновационные» и «эксклюзивные», а российские аналоги получают сдержанные характеристики вроде «надёжности» или «функциональности». Само понятие «премиум» в данных связано с западными маркетинговыми нарративами.
Это напрямую влияет на потребителей, которые воспринимают ИИ-ассистентов как объективных советчиков. Игнорирование российских брендов лишает людей возможности полноценного выбора, ведя к неоптимальным покупкам.
Чтобы преодолеть этот барьер, бизнесу необходимо действовать системно, фокусируясь на изменении своего цифрового следа. Эксперты выделяют несколько ключевых стратегий, которые помогут российским компаниям вернуть видимость и нивелировать эффект «цифрового снобизма».
Прежде всего, компаниям стоит расширить присутствие в англоязычном цифровом пространстве. Поскольку обучающие выборки больших языковых моделей насыщены именно таким контентом, отсутствие информации о бренде на английском языке делает его невидимым для ИИ или ставит его в положение аутсайдера. Создание качественного контента на международных платформах позволит переломить эту тенденцию и дать нейросетям материал для объективной оценки.
Не менее важно пересмотреть семантическое наполнение описаний товаров и услуг. Исследования показывают, что российские бренды чаще ассоциируются алгоритмами с «функциональностью» и «надёжностью», в то время как маркеры «премиум» и «инновации» закрепляются за западными компаниями. Чтобы изменить алгоритмическое восприятие, в маркетинговых материалах нужно сместить фокус с утилитарных характеристик на уникальность, технологичность и эксклюзивность.
Техническая оптимизация данных также играет решающую роль. Видимость в ИИ-поиске напрямую зависит от того, насколько структурирована информация о компании. Если уникальные атрибуты товара и характеристики бренда представлены в разрозненном виде, нейросеть не сможет их извлечь и порекомендовать потребителю. Чёткая структура данных повышает шансы попасть в поле зрения алгоритмов.
Кроме того, бизнесу не стоит пренебрегать региональным присутствием. Как показал анализ, сильный локальный цифровой след значительно повышает видимость бренда в рекомендациях для конкретного региона. Развитие репутации и упоминаний в региональных медиа помогут компенсировать федеральные перекосы и обеспечить стабильный поток рекомендаций.
И наконец, для разрыва порочного круга предвзятости необходимо активно формировать массив позитивных экспертных мнений. Поскольку алгоритмы усиливают существующие паттерны, внешнее подтверждение высокого статуса бренда — профессиональные обзоры, награды и публикации — создаст новую базу данных, на основе которой ИИ сможет формировать более объективный и благоприятный образ российских компаний.
ИИ рискует стать «цифровым диктатором вкуса», навязывая предвзятые предпочтения. Для бизнеса это выражается в потере продаж и доли рынка, особенно в премиум-сегменте. Постоянное позиционирование как аутсайдеров наносит репутационный ущерб и усложняет выход на международные рынки. Решение проблемы требует системного подхода и работы над цифровым присутствием.
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на 42@cossa.ru. А наши требования к ним — вот тут.
Популярные новости
7 апреля 2026, 02:20
7 апреля 2026, 02:16
3 апреля 2026, 17:43