Как проработать семантическое ядро с помощью Key Collector. Часть 1
Рассказываем, как собрать качественное семантическое ядро: подбор масок, добавление и парсинг в Key Collector.

Любая рекламная кампания в контексте начинается со сбора семантического ядра. От ключевых слов и фраз, на основе которых пользователям показывается рекламное объявление, во многом зависит успех рекламной кампании.
Критерии качественного семантического ядра
-
Для заданной РК подобраны все возможные релевантные маски. (Маска — основное слово или словосочетание в запросе, на базе которого создаётся длинный список из различных ключевых фраз.)
-
По каждой маске собраны все вложенные ненулевые запросы из всех известных источников сбора.
-
Из каждой маски «отминусованы» все нецелевые слова.
-
Проведена кросс-минусовка ключевых слов.

Тест SEO 2 недели
В топ за 2 недели бесплатно. Предоплата не нужна.
Подключай тест-драйв SEO в PromoPult:
- Подберем ключевые слова.
- Выполним задачи по базовой оптимизации.
- Проставим ссылки с надежных сайтов.
- Создадим контент под информационные запросы.
Реклама. ООО «Клик.ру». ИНН 7743771327. ОГРН 1107746150126
Ускорить сбор позволяет Key Collector.
Подбираем маски
Пробиваем маски через Wordstat и ищем похожие запросы.
Пример: собираем РК для бокс-клуба. Наши маски: «записаться на бокс», «занятия боксом» и т. д. Само слово «бокс» слишком широкое по смыслу. Включить его в нашу РК даже в точном соответствии нельзя. Но мы можем пробить слово «бокс» (уточнённое высокочастотными минус-словами) через Wordstat и найти ещё несколько масок, например, «абонемент на бокс», «тренера по боксу» и т. п.
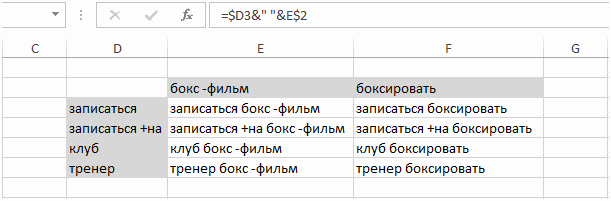
Кроме того
-
Изучайте отчёты по реальным поисковым фразам в «Яндекс.Метрике» и Google AdWords.
-
Используйте сервисы подбора синонимов.
-
Пользуйтесь формулами сцепки в Excel или сервисами перемножения. Excel позволяет рассортировать все полученные маски «по полочкам», точнее, по столбикам. Сервис перемножения, наоборот, формирует единый столбец. Что удобнее — зависит от ситуации.
-
Используйте минус-слова уже на уровне масок для уточнения запросов. Например, мы собираем ядро для шкафов, предназначенных для разных помещений. Очевидные маски: «Шкаф гостиная», «Шкаф прихожая» и т. д. Но также можно пробить «Шкаф -духовой -холодильный» — этими минусами мы отсеем половину мусора уже на входе.
-
Пользуйтесь операторами «+» и «!», чтобы вытянуть большее количество слов из Wordstat. (Знак «!» фиксирует падеж и число слова, а «+» нужен для принудительного учёта предлогов и союзов.) По запросу с использованием операторов Wordstat выдаёт новую выборку, в которой могут оказаться и новые слова.
Пример: пробиваем маску «купить шкаф». Wordstat выдаёт фразы со следующей частотностью:
-
«купить шкаф» (100 000 показов);
-
«купить шкаф москва» (50 000 показов);
-
«купить шкаф недорого» (10 000 показов).
-
...
Далее пробиваем маску «Купить шкаф +в» — и тут Wordstat выдаёт новую картинку:
-
«купить шкаф +в» (70 000 показов);
-
«купить шкаф +в спальню» (40 000) показов;
-
...
Во вторую выборку попал запрос «купить шкаф +в спальню» (40 000 показов). Это вложенная фраза для «Купить шкаф». Судя по количеству показов, она должна оказаться в первой выборке между фразами «Купить шкаф москва» (50 000) и «Купить шкаф недорого» (10 000), но её там нет.
Добавляем маски в Key Collector
Следующий шаг — добавить слова на парсинг в Key Collector.
В простом случае переносим все маски в один столбец и копируем получившийся список.
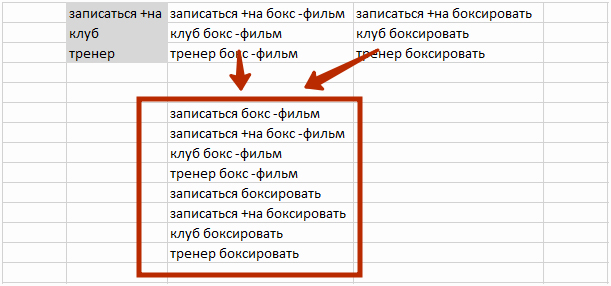
Далее выбираем инструмент «Пакетный сбор фраз из левой колонки Wordstat», вставляем слова из буфера обмена, проверяем наличие галочки на опции «Не добавлять фразу, если она уже есть в любой другой группе» (тут возможны исключения) — и жмём на кнопку «Распределить все фразы по одноимённым группам».
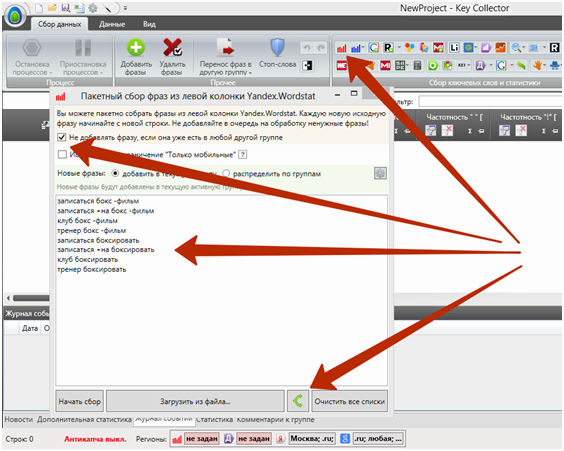
Таким образом мы автоматически создаём в проекте группу под каждую маску:
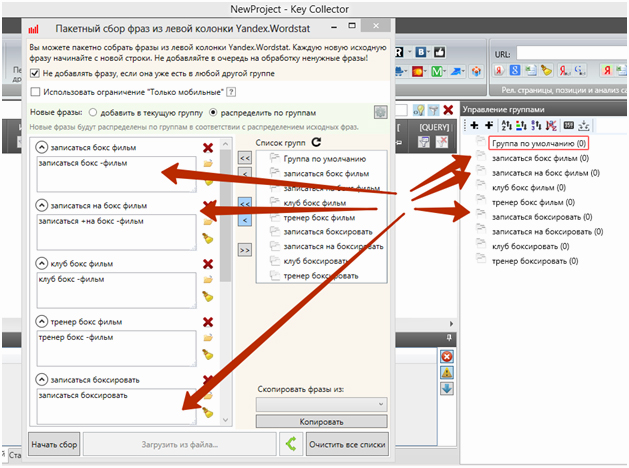
Почему лучше не собирать все маски в единой группе?
Во-первых, при большом количестве масок Key Collector работает медленно (но в разы быстрее, чем человек). Когда у вас «спарсится» первая подгруппа, вы уже сможете с ней работать — минусовать, группировать, анализировать. Параллельно будут собираться и остальные подгруппы. Этот подход здорово экономит время, когда нужно оперативно «спарсить» маски.
Во-вторых, если ядро новое и незнакомое, вы не знаете, как поведёт себя та или иная маска. Некоторые из них (на вид безобидные ![]() ) могут оказаться чертовски мусорными. Например, при сборе РК по видеонаблюдению в маске «камера школа» мы нашли уйму порно и куда меньше запросов о видеонаблюдении. Если решите собирать всё в одной группе, а в список попадёт такая маска, у вас в один лист «спарсится» 10 000 слов, 5000 которых будут мусорными.
) могут оказаться чертовски мусорными. Например, при сборе РК по видеонаблюдению в маске «камера школа» мы нашли уйму порно и куда меньше запросов о видеонаблюдении. Если решите собирать всё в одной группе, а в список попадёт такая маска, у вас в один лист «спарсится» 10 000 слов, 5000 которых будут мусорными.
В результате вам придётся несколько часов вычищать неподходящие фразы. Разумнее парсить в разные группы — тогда маска «камера школа» будет стоять особняком.
Другая крайность: масок очень много (больше 200–300). Раскидывать их по отдельным группам долго, да и нагрузка на программу неоправданно высокая. В таком случае создаём отдельную группу не под одну, а под несколько масок, желательно близких по смыслу. Обычно это столбцы или строки из нашей матрицы масок. Для этого приёма необходимо выбрать способ группировки (например, по столбцам):
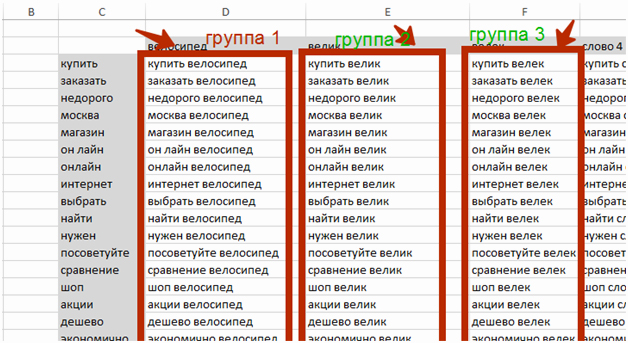
Затем копируем заголовки групп и вставляем их в инструмент сбора Key Collector, жмём «Распределить все фразы по одноимённым группам» — и получаем список выбранных групп:
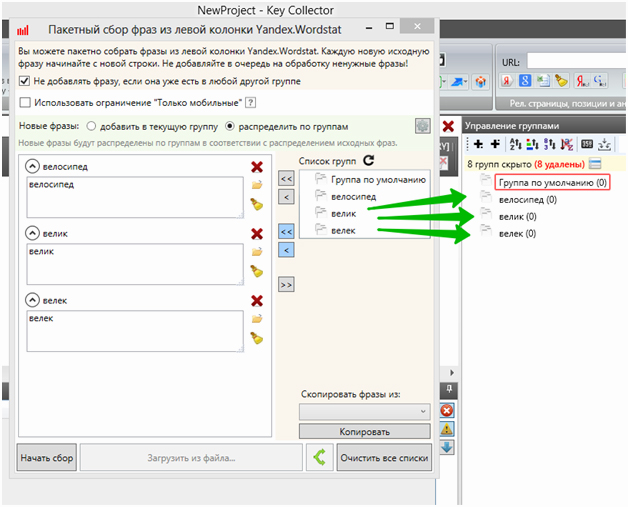
Удаляем из них первые слова (это просто названия столбцов) и вставляем сами группы:
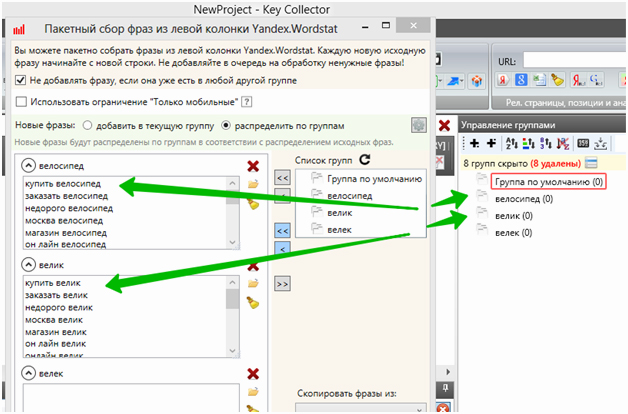
Важный момент. Если используете в списке масок операторы или минус-слова, перед добавлением этих слов в Key Collector проверьте в настройках, не включено ли автоматическое удаление символов:
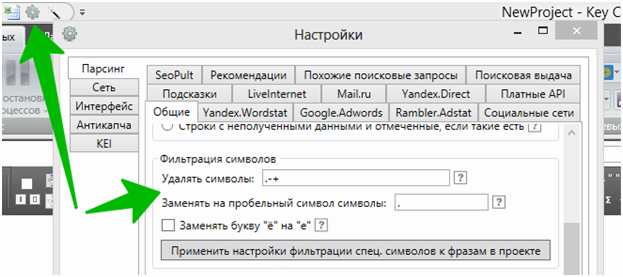
В противном случае фраза «Шкаф +в Москве — холодильный» отправится на парсинг как «Шкаф в Москве холодильный».
Парсинг
Далее переходим к следующему шагу — жмём «Начать сбор»:
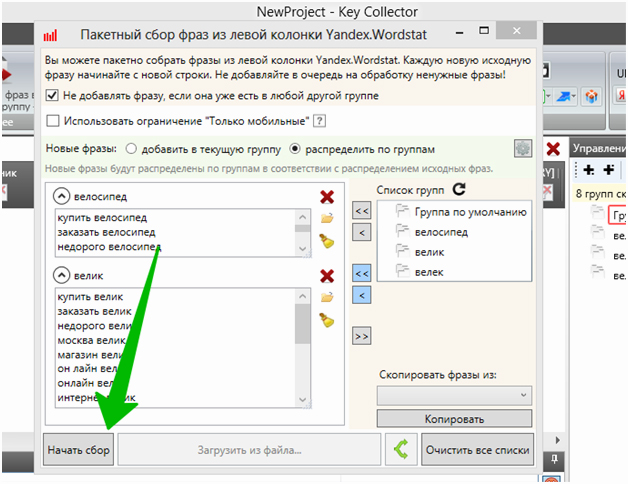
Обратите внимание: если перед добавлением слов в проект вы отключали удаление знака «+», то перед парсингом нужно вернуть его обратно. Если, конечно, вы не хотите, чтобы слова попадали в «вордстатовском» виде, например, «купить шкаф +в москве +на таганке».
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед». Профит!
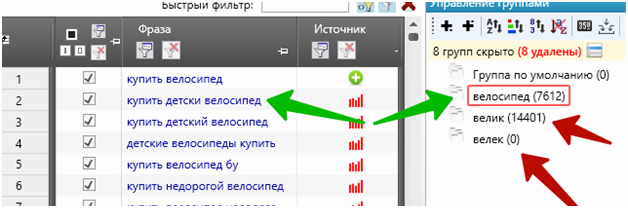
После минусовки рекомендуем «спарсить» ядро ещё несколько раз, так как у каждой собранной ключевой фразы могут быть вложенные фразы, которые не «спарсились» на первом круге. Собранное «отминусованное» ядро в таком случае будет новым списком масок.
Повторно следует «парсить» не все слова, а только высоко- и среднечастотные запросы, так как в низкочастотных вложенных запросов почти не будет.
Чтобы понять, как много вложенных запросов у конкретного слова, можно снять его частотность в широком и в точном соответствии, а затем поделить широкое на точное. Чем больше соотношение, тем больше в ключевике вложенных фраз. Это такой себе «коэффициент замусоренности». Также вложенные запросы можно почистить через прогнозатор «Яндекс.Директа». Кому как удобнее.
А после завершения парсинга не забудьте прогнать полученные фразы через инструмент KC «Анализ неявных дублей». Он поможет найти в списке дубли в стиле «купить велосипед москва» и «купить велосипеды в москве» — и удалить их по заданным условиям.
В следующей части статьи мы расскажем, как отминусовать ненужные слова, сгруппировать нужные, перенести данные в Excel и подготовить объявления для «Яндекс.Директа» или Google AdWords.
Авторы статьи:
Анастасия Якунина, production-менеджер в Adventum,
Артур Семикин, performance-менеджер в Adventum.
Читайте далее: Как проработать семантическое ядро с помощью Key Collector. Часть 2
Мнение редакции может не совпадать с мнением автора. Если у вас есть, что дополнить — будем рады вашим комментариям. Если вы хотите написать статью с вашей точкой зрения — прочитайте правила публикации на Cossa.
Популярные новости
7 июля 2025, 16:57
4 июля 2025, 15:42
3 июля 2025, 13:07
3 июля 2025, 10:49