Как прогнозируют выручку с помощью больших данных — кейс алкогольного магазина
Как модные «большие данные», «искусственный интеллект» и «машинное обучение» несут реальную пользу ритейлерам. Рассказывает руководитель продуктового направления «Ритейл» oneFactor Евгений Максимча.

В 2018 году мы совместно с уральским алкогольным ритейлером «МАВТ-Винотека» провели пилотный проект по оценке потенциала локаций перед открытием новых торговых точек. Для этого применяли большие данные и машинное обучение.
В общей сложности пилотный проект занял полтора месяца. В результате нам удалось повысить точность прогнозирования выручки для новой торговой точки в четыре раза (относительно среднего по рынку) и внедрить полученную модель в существующий бизнес-процесс заказчика.
А зачем ритейлерам большие данные?
Важно отметить, что прогноз потенциальной выручки новой локации перед открытием — головная боль для любого ритейлера.
Спрогнозировать выручку для существующей торговой точки можно на основе её исторических данных, применив пару-тройку «экспертных коэффициентов». А вот в случае с новой локацией истории продаж нет, но решение об открытии принимать надо.
Какие факторы учитывать в таком случае и на что обратить внимание в первую очередь? Наш ответ — использовать большие данные и машинное обучение для прогнозирования.
Основной принцип работы машинного обучения заключается в поиске зависимости между группой факторов и каким-то целевым показателем (выручка, количество чеков, количество клиентов и так далее).
Например: X*население в радиусе локации + Y*средний доход населения = ожидаемая выручка.
Фактически наша задача заключалась в поиске такой формулы, которая моделирует бизнес «МАВТ-Винотеки» с учётом множества факторов в привязке к географической точке и очень точно переводит эти факторы в прогнозируемую выручку в рублях.
В ходе решения возник ряд вопросов:
- какие факторы необходимо заложить в формулу оценки локации?
- как определить X и Y («важность» каждого из факторов)?
- как проверить, что формула правильная?
Если вспомнить школьные задачники по математике, то в конце каждого из них всегда есть ответы, которые можно использовать для тренировки навыков решения перед контрольной работой.
По такому же принципу и работает машинное обучение.
- Научиться решать примеры, заранее зная ответ (в нашем случае это существующие локации, выручка которых нам известна, то есть их мы можем использовать для создания модели машинного обучения).
- Применить полученные знания на контрольной (для нас это новые точки, выручка по которым неизвестна).
Так мы и действовали.
Какие факторы заложить в формулу оценки локации?
Интуитивно понятно, что на выручку торговой точки влияют следующие факторы:
- численность населения;
- доход населения;
- конкуренция;
- удобство локации;
- и другие очевидные данные.
Интуитивно, может, и понятно, но как оценить все эти факторы?
Численность населения
Одними из наших поставщиков «больших данных» являются мобильные операторы, на основании которых можно оценить реальную численность населения в радиусе интересующей локации.
«Сырые» геоданные от мобильных операторов выглядят на карте как квадраты 500×500 метров, что не очень подходит для оценки конкретной географической точки. К счастью, внутри нашей oneFactor уже 5 лет развивается платформа GeoMind, которая уточняет «сырые» данные от мобильных операторов с точностью до 50 метров, что и позволило нам оценить население вокруг каждой локации «МАВТ-Винотеки» с максимальной точностью.
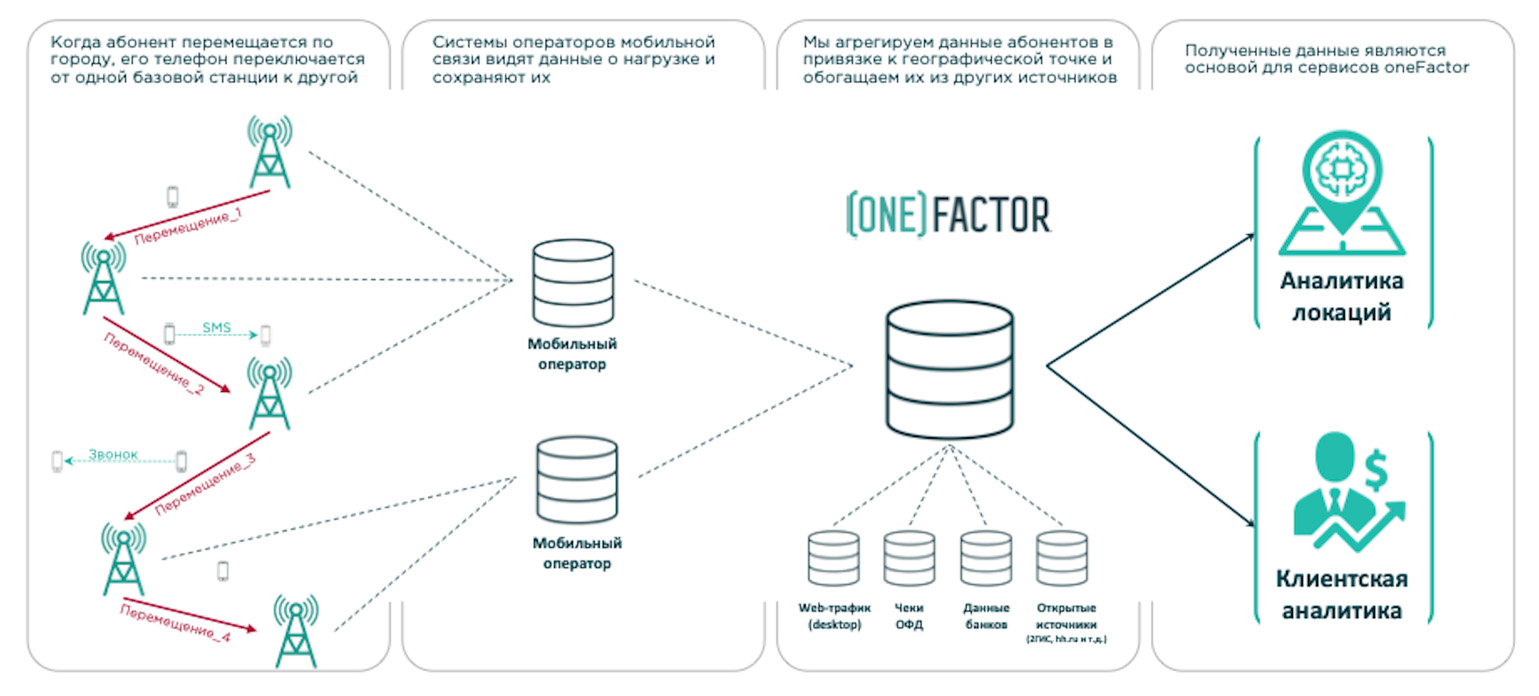
Кстати, по нашим исследованиям, реальная численность населения Челябинска на 18% ниже данных по результатам переписи.
Доход населения
Данный фактор мы определяли также на основании анонимизированных данных мобильных операторов и поведенческих характеристик абонентов. Наши внутренние модели машинного обучения позволяют оценить уровень дохода абонента с точностью 86%.
Конкуренция
Данные о расположении конкурентов можно найти в любом открытом источнике, но что конкретно из себя представляет фактор «конкуренция»?
Возможные интерпретации:
- количество конкурентов в разных радиусах;
- расстояние до ближайшего конкурента в метрах;
- суммарный доход населения в радиусе локации, делённый на количество конкурентов (вот оно, преимущество нескольких источников больших данных);
...и ещё более 20 различных интерпретаций.
На всякий случай, мы взяли сразу все.
Удобство локации
Под этим фактором можно подразумевать:
- расстояние до ближайшей транспортной остановки;
- азимут входа в магазин (чтобы оценить «видимость» потенциальной вывески);
- ранг локации относительно конкурентов по пути «остановка → дом». Например, второй по счёту продуктовый магазин, когда я иду домой. Кстати, для каждого дома в радиусе локации это число будет разное, и это тоже хорошо бы учесть.
Правильная интерпретация? Сразу все.

Мы привели только примеры, но далеко не полный список. В конечном итоге каждая из существующих локаций «МАВТ-Винотеки» была описана более чем 200 факторами, причём каждый из них имел разные значения в зависимости от анализируемого месяца, которых было 24.
На языке машинного обучения — мы создали «признаковое пространство», которое далее было использовано для оценки важности каждого из факторов и построения формулы зависимости.
Как определить X и Y («важность» каждого из факторов)?
Описать каждую локацию, создав признаковое пространство, это только полдела. Следующий шаг — оценить степень влияния каждого из признаков на выручку и получить формулу зависимости.
Именно на этом этапе и начинается «машинное обучение»: если в классических исследованиях вес факторов определяется экспертно, то мы использовали искусственный интеллект, который проанализировал влияние каждого из 200+ параметров на выручку существующих точек за период в 24 месяца.
С этой задачей искусственный интеллект справляется куда лучше любого «живого» аналитика — факторов очень много и одновременно держать их в голове просто невозможно.
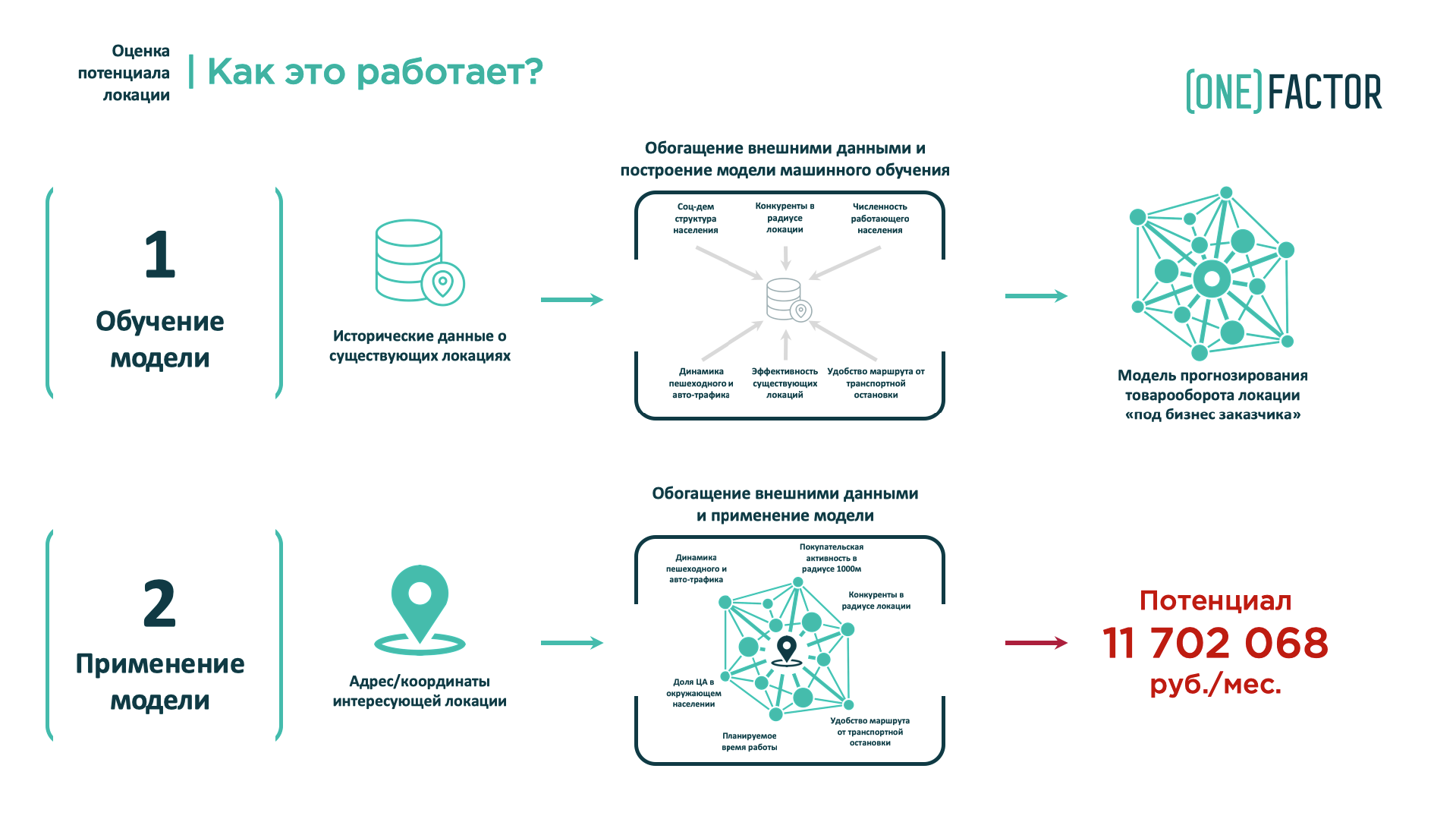
Как проверить, что формула правильная?
На данном этапе мы проверяли формулу, которую искусственный интеллект предложил как наиболее подходящую для моделирования выручки торговой сети «МАВТ-Винотеки».
Задача, которую решала команда oneFactor, носит специфичный характер, так как для реального эксперимента необходимо открывать новые торговые точки и ждать, пока они выйдут на «полную мощность» (в среднем 3 месяца), что, мягко говоря, не очень разумно для первичного тестирования модели, даже если её предложил искусственный интеллект. Поэтому перед началом проекта мы разделили существующие локации в пропорции 80/20:
- 80% локаций использовали для обучения модели;
- 20% оставшихся локаций не показывали искусственному интеллекту и оставили для тестирования.
Перед полевым тестированием мы применили модель для оценки тестовых локаций, чтобы понимать примерную точность, которую стоит ожидать в полях. Первый заход, как это часто бывает, оказался не очень успешным, но мы не расстраивались, так как любые исследования всегда очень интересны.
Мы начали переобучать модель, изменяя входящие факторы. Например: население в радиусе 500 метров давало куда меньший прирост точности, чем население в радиусе 300 метров, но ещё больший прирост точности достигается, если использовать не просто численность населения, а именно количество мужчин в возрасте 25–45 с уровнем дохода выше среднего. К этому выводу мы пришли, проанализировав клиентскую базу «МАВТ-Винотеки».
Через несколько итераций переобучения мы смогли достичь точности, которой можем гордиться, — на тестовых локациях наша модель ошибалась не более чем на 10% в 93% случаев. На данном этапе мы ощутили внутреннюю уверенность идти в полевое использование и внедрили полученную модель в существующий бизнес-процесс оценки локаций «МАВТ-Винотеки».
Сейчас при продуктивном использовании разработанной модели машинного обучения мы достигаем отклонения до 10% в 82% случаев, в то время как оценка новой локации занимает не более 48 часов (ранее это было 3 недели). В рамках полевого тестирования мы замеряем точность через 3 месяца после открытия, так как первые месяцы локация «раскачивается» и только заявляет о себе населению.
Важно отметить, что чем чаще наши заказчики используют модель в продуктивном режиме, тем точнее она становится — искусственный интеллект обучается на новых данных, которые появляются с каждым новым месяцем и с каждой новой открытой точкой.
Какие выводы мы сделали
- Очень важно работать с заказчиком в атмосфере доверия, это позволяет обмениваться идеями, качественно погрузиться в особенности работы бизнеса и в результате построить точную модель. С «МАВТ-Винотекой» мы изначально работали в рамках доверительных партнёрских отношений и помогали друг другу, за что хотим выразить благодарность от всей компании oneFactor.
-
Из вопроса доверия вытекает другой немаловажный аспект — готовность заказчика делиться историческими данными с целью построения модели машинного обучения. Любой сколь угодно умный искусственный интеллект не сможет хорошо спрогнозировать выручку локаций только на данных о населении, не учитывая особенностей бизнеса. Чем больше данных имеется у клиента и чем они точнее, тем лучше результат. Практически невозможно составить хорошую модель, если использовать данные за 1–3 месяца, так как при этом теряется связь с макроэкономическими показателями. В идеале нужно использовать всю возможную историю продаж, которая есть у заказчика.
- До получения первых результатов работы модели переживать об уровне точности конкретных входящих факторов не стоит. Наша реальная задача — спрогнозировать выручку локации, а не оценить количество работающего населения в радиусе 243 метров. Вполне возможно, этот фактор даже не будет влиять на конечный результат, и это останется лишь нашей гипотезой.
Рекомендуем:
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на 42@cossa.ru. А наши требования к ним — вот тут.
Популярные новости
30 июня 2025, 15:26
30 июня 2025, 13:28
30 июня 2025, 10:20
Продавцы интернет-магазинов получили новые возможности для управления репутацией через Яндекс Товары
27 июня 2025, 14:59
27 июня 2025, 10:03