Stable Diffusion для решения задач клиентов: эксперты icontext протестировали нейросеть
Что из себя представляет нейросеть Stable Diffusion и как ее использовать, читайте в статье.
Источник статьи: блог iConText Group.
Автор статьи: Артем Попов, руководитель направления new media icontext (iConText Group)
С момента массового появления нейросетей на рынке основными точками применения стали тексты и изображения. Если в случае с текстами наши запросы сегодня вполне закрываются возможностями Chat GPT 4.0 и Bard от Google, то в случае с изображениями требуется гораздо больше инструментов для работы и опций для тонкой настройки.
Наш опыт показывает, что текущие сервисы, такие как Midjourney или Кандинский 2.2, достойно справляются со своими задачами, но у них есть особенности, которые нужно учитывать. В частности, ограниченные возможности корректировки определенных частей изображения или возможность генерации создавать длинные видео на основе морфинга.
При этом, как агентству, нам важно иметь постоянный доступ к системе генерации и не зависеть от внешних сервисов. Кроме того, большую роль играет возможность дорабатывать, докручивать и улучшать используемую систему. Поэтому, когда встал вопрос о следующем этапе внедрения генеративных ИИ в задачи агентства, мы обратили внимание на нейросеть от Stable Diffusion.
Наш опыт показывает, что текущие сервисы, такие как Midjourney или Кандинский 2.2, достойно справляются со своими задачами, но у них есть особенности, которые нужно учитывать. В частности, ограниченные возможности корректировки определенных частей изображения или возможность генерации создавать длинные видео на основе морфинга.
При этом, как агентству, нам важно иметь постоянный доступ к системе генерации и не зависеть от внешних сервисов. Кроме того, большую роль играет возможность дорабатывать, докручивать и улучшать используемую систему. Поэтому, когда встал вопрос о следующем этапе внедрения генеративных ИИ в задачи агентства, мы обратили внимание на нейросеть от Stable Diffusion.
Что такое Stable Diffusion
Stable Diffusion — open-source нейросеть для генерации изображений по текстовому запросу, которая доступна на сайте и в версии для скачивания, выпущенная Stability.ai в августе 2022 года.
Модель очень быстро нашла признание благодаря возможностям кастомной донастройки под конкретные цели пользователя. А это важно, если перед вами стоит нетривиальная задача.
Ее главная сильная сторона — кастомные модели генерации, обученные на разнообразных датасетах и позволяющие генерировать совершенно разные по стилистике и визуалы изображения.
Также с помощью нейросети можно дорисовывать изображения, превращая схематические наброски в иллюстрации, и изменять картинки. Например, расширить фон, удалить конкретный объект или заменить его на другой.
Модель очень быстро нашла признание благодаря возможностям кастомной донастройки под конкретные цели пользователя. А это важно, если перед вами стоит нетривиальная задача.
Ее главная сильная сторона — кастомные модели генерации, обученные на разнообразных датасетах и позволяющие генерировать совершенно разные по стилистике и визуалы изображения.
Также с помощью нейросети можно дорисовывать изображения, превращая схематические наброски в иллюстрации, и изменять картинки. Например, расширить фон, удалить конкретный объект или заменить его на другой.
Как мы тестировали Stable Diffusion
После установки этой нейросети мы получили open-source модель с открытой лицензией и возможностью постоянного обновления — к тому же, крайне гибкую.
Это позволяет не зависеть от изменений, вносимых в системы других генеративных ИИ, которые, например, не всегда удачно вписываются в текущие задачи клиентов. В отличие от закрытых систем (как MidJourney), здесь можно самим выбрать и установить те модели генерации, которые максимально подойдут для решения задач клиента в конкретный момент. А наличие разных моделей сэмплинга внутри позволяет более точно и детально настраивать стиль и визуализацию запрашиваемого изображения.
Например, сейчас мы используем несколько установленных моделей, которые максимально заточены на получение реалистичных изображений людей. Чуть ниже вы видите пример работы модели Realistic Vision с сэмплинг Euler_a:
Это позволяет не зависеть от изменений, вносимых в системы других генеративных ИИ, которые, например, не всегда удачно вписываются в текущие задачи клиентов. В отличие от закрытых систем (как MidJourney), здесь можно самим выбрать и установить те модели генерации, которые максимально подойдут для решения задач клиента в конкретный момент. А наличие разных моделей сэмплинга внутри позволяет более точно и детально настраивать стиль и визуализацию запрашиваемого изображения.
Например, сейчас мы используем несколько установленных моделей, которые максимально заточены на получение реалистичных изображений людей. Чуть ниже вы видите пример работы модели Realistic Vision с сэмплинг Euler_a:

Кстати, наличие возможности корректировки изображения позволяет быстро подправить понравившееся изображение. Скажем, немного переконфигурировать лицо:

Помимо Realistic Vision, мы начали использовать и другие модели, каждая из которых может давать необычный результат. Это позволяет не только создавать уникальные изображения для клиентов, но побуждает сотрудников пробовать что-то новое, тренировать навыки промт-инжиниринга.
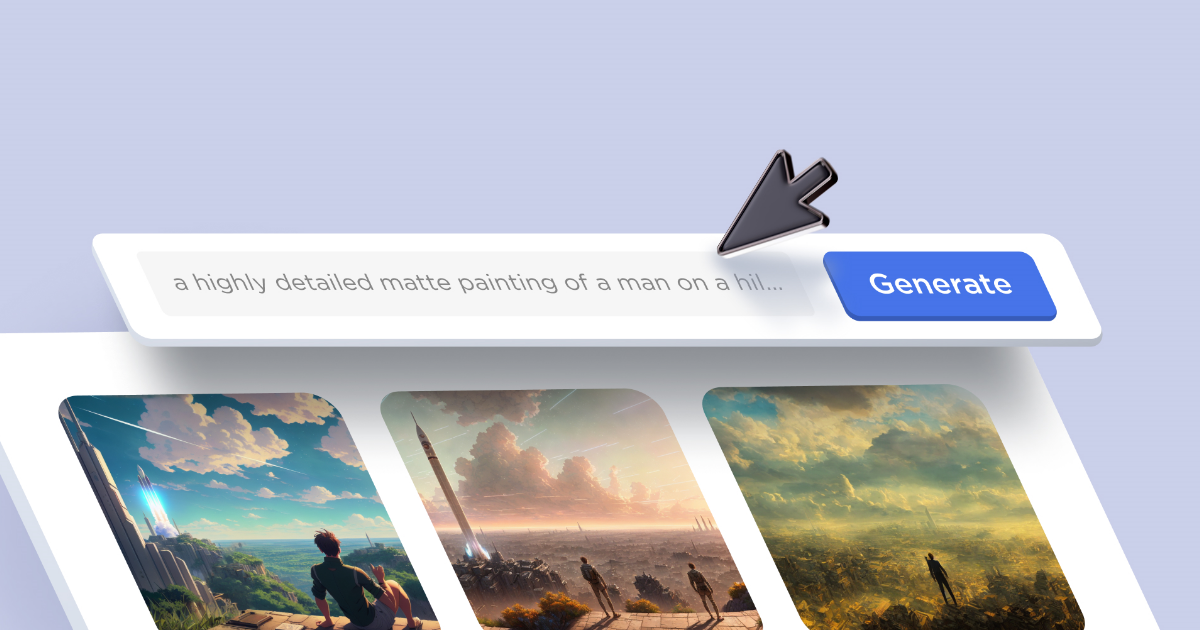
Попробуем показать наглядно. Мы сделали немного необычный запрос и протестировали пять моделей, чтобы показать, как по-разному они видят один и тот же запрос. Наш запрос звучал так:
a highly detailed matte painting of a man on a hill watching a rocket launch in the distance by studio ghibli, makoto shinkai, 4 k resolution, trending on artstation, masterpiece
Seed: 155355667 Steps: 150
Итак, что мы видим?
Модель Dreamlike Photoreal сформировала изображение максимально близко к тексту промта, сделав его красочным и весьма детальным:
 *Stable diffusion 1.5 generative image, model dreamlike photoreal, seed 155355667, steps 150
*Stable diffusion 1.5 generative image, model dreamlike photoreal, seed 155355667, steps 150
Модель Deliberate, наоборот, ушла в сторону, скорее, кинематографичного 3D:
 *Stable diffusion 1.5 generative image, model Deliberate, seed 155355667, steps 150
*Stable diffusion 1.5 generative image, model Deliberate, seed 155355667, steps 150
Завораживающий результат получился у вышеупомянутой модели Realistic Vision. Она представила запрос как светлую версию киберпанка с городом, простирающимся за горизонт:
 *Stable diffusion 1.5 generative image, model realistiс vision, seed 155355667, steps 150
*Stable diffusion 1.5 generative image, model realistiс vision, seed 155355667, steps 150
А вот базовая модель Stable Diffusion 1.5 и F222 дали очень похожий и в то же время сильно отличный от ожиданий и вариантов других моделей результат. От картинок есть ощущение смешения нескольких стилей и разных визуальных рядов, при этом сильно хромает детализация дальних планов:
 *Stable diffusion 1.5 generative image, model standard, seed 155355667, steps 150
*Stable diffusion 1.5 generative image, model standard, seed 155355667, steps 150
 *Stable diffusion 1.5 generative image, model F222, seed 155355667, steps 150
*Stable diffusion 1.5 generative image, model F222, seed 155355667, steps 150
Приведенные примеры наглядно показывают, как сильно может различаться результат в зависимости от использования той или иной модели при одном и том же запросе и способе сэмплинга.
Если учесть, что все генеративные модели будут идти к определенной степени открытости и росту числа доступных для корректировки инструментов, для агентств и рынка в целом особенно важно как можно быстрее набирать опыт работы с промтами и разными моделями.
Если учесть, что все генеративные модели будут идти к определенной степени открытости и росту числа доступных для корректировки инструментов, для агентств и рынка в целом особенно важно как можно быстрее набирать опыт работы с промтами и разными моделями.
Генерация видео с помощью Stable Diffusion
Хочется обратить внимание и на еще одну важную и весьма полезную функцию Stable Diffusion — генерацию видео. Конечно, уже сейчас есть генеративные ИИ, способные делать реалистичные видео. Но выглядят они достаточно спорно и пока еще вызывают множество вопросов.
Однако Stable Diffusion дает возможность создавать небольшие видеоролики, используя морфинг изображений. Это позволяет оперативно создавать креативы для тех клиентов, кому нужно, например, протестировать иной визуальный стиль или новый нарратив, а возможно, они просто не могут в моменте сделать продакшн видео.
Например, на основе промт-запросов был сгенерирован достаточно простой, но в то же время весьма притягивающий внимание видеоролик. И как вы понимаете, это только начало.
Резюмируя историю с Stable Diffusion и ее возможностями стоит сказать следующее:
Однако Stable Diffusion дает возможность создавать небольшие видеоролики, используя морфинг изображений. Это позволяет оперативно создавать креативы для тех клиентов, кому нужно, например, протестировать иной визуальный стиль или новый нарратив, а возможно, они просто не могут в моменте сделать продакшн видео.
Например, на основе промт-запросов был сгенерирован достаточно простой, но в то же время весьма притягивающий внимание видеоролик. И как вы понимаете, это только начало.
Резюмируя историю с Stable Diffusion и ее возможностями стоит сказать следующее:
- Нейросети будут и дальше обрастать дополнительными возможностями генерации и корректировки изображений.
- Большое количество возможностей и настроек приведут к появлению специалистов, которые будут очень тонко и детально понимать, как настроить тот или иной запрос для нейросети.
- Несмотря на все заверения, что промты скоро окажутся под капотом, пока нет иного эффективного способа донести до ИИ, что вы хотите, кроме как живым языком.
- Открытые нейросетевые модели — будущее для точечных задач и энтузиастов, которые хотят сделать лучше и не так, как у всех. Поэтому нужно не бояться экспериментировать.
Источник статьи: блог iConText Group.
Рекомендуем!
Популярные новости
29 апреля 2024, 13:07
26 апреля 2024, 12:24