Как почистить семантическое ядро от дублей и мусора
Нормализатор слов: бесплатно убираем все эти плюсы, знаки вопроса, лишние пробелы и «нулевки»

Для максимального охвата целевой аудитории в поиске необходимо собрать исчерпывающее семантическое ядро. Иногда это сотни, иногда тысячи, а иногда и десятки и сотни тысяч запросов — в зависимости от объема сайта и конкуренции в тематике.
Чтобы семантика полностью отражала спрос, нужно использовать разные источники — сервисы поисковых систем, поисковые подсказки, фразы-ассоциации и другие (подробно о сборе запросов мы писали в гайде).
При подборе ключевиков неизбежно прямое или косвенное их дублирование (например, «чай каталог» и «каталог чая»), попадание в список спецсимволов, лишних пробелов, слов с прописными буквами. Собрать полное семантическое ядро и удалить «мусорные» запросы вручную — задача рутинная, но нужная.
Мы покажем, как собрать и почистить семантическое ядро с помощью бесплатных автоматизированных инструментов PromoPult на примере чайного магазина.
Первоначальный сбор и расширение семантического ядра
Сначала составляется базовый перечень фраз, описывающих бизнес. Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
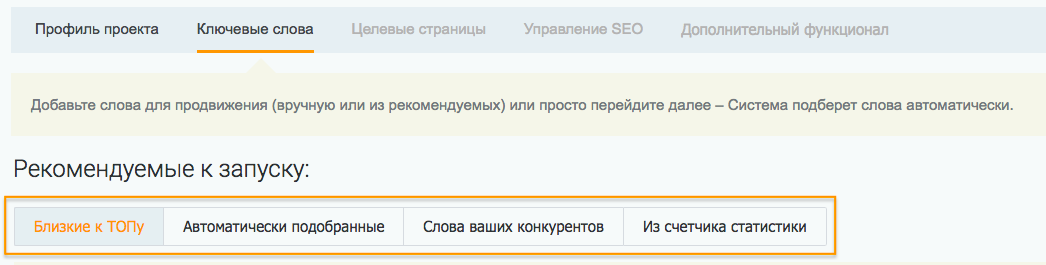
Переключаясь на вкладки, генерируйте запросы и подходящие добавляйте в опорный список для расширения.
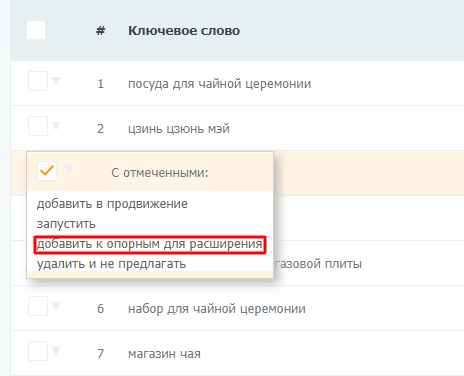
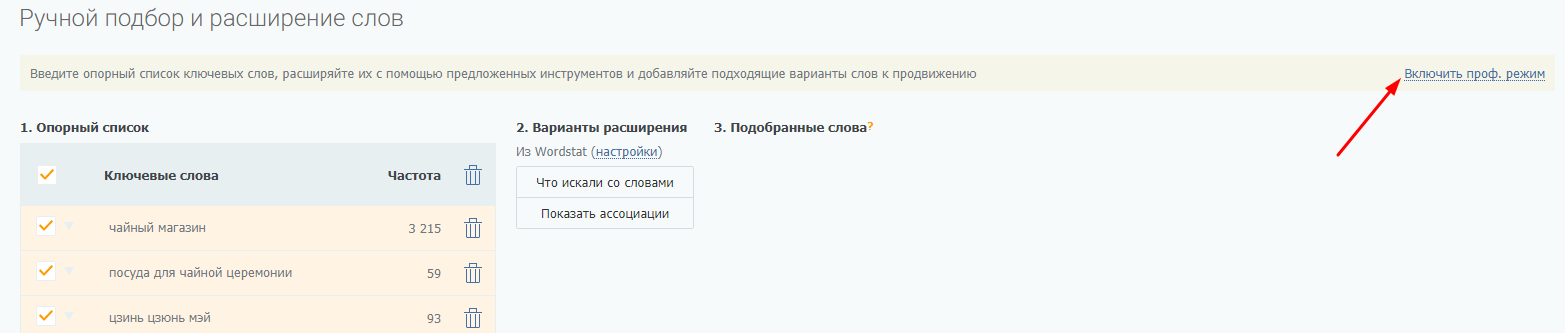
Когда опорный список готов, переходите к расширению. Для этого понадобится раздел «Ручной подбор и расширение слов». Включите профессиональный режим:
Далее базовый список расширяйте в ширину с помощью правой колонки Вордстат (смежные по значению запросы) — кнопка «Показать ассоциации». Обязательно ознакомьтесь с рекомендациями по выбору числа страниц для парсинга (они будут во всплывающем окне после клика по ссылке «настройки»).
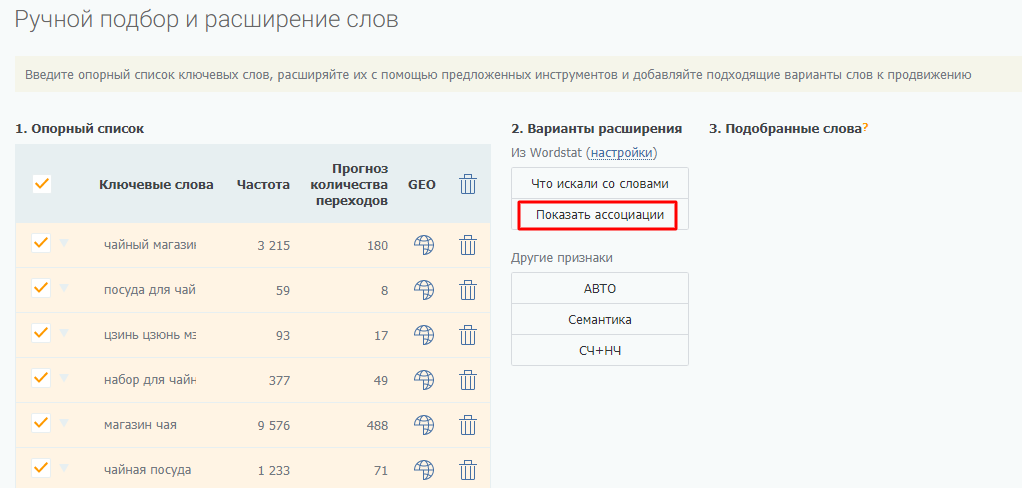
Найденные слова и фразы, которые отвечают тематике, добавляйте в опорный список к базовым запросам.
Затем опорный список расширяйте в глубину с помощью левой колонки Вордстат (другие фразы с вхождением ключа) – кнопка «Что искали со словами»:
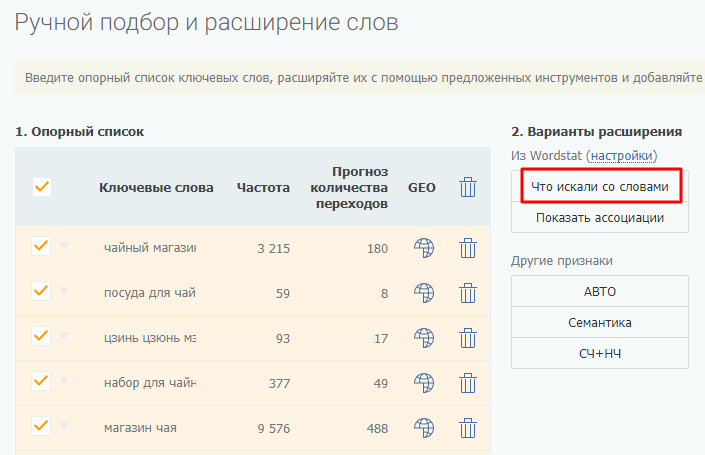
Если слов очень много (более тысячи) и система начинает работать медленно, операцию можно проводить поэтапно. Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Для «ширины» есть еще пара профессиональных инструментов PromoPult, для которых мы написали подробные инструкции:
парсер фраз-ассоциаций (блок выдачи «вместе с запросом ищут»).
Прогоните через них базовый (начальный) список запросов и добавьте спарсенные слова в общий Excel-файл.
Собрать такой список — полдела.
В ядро могут попадать нерелевантные тематике фразы и мусор в виде дублей запросов, лишних символов, фраз с нулевой частотностью. Список обязательно нужно чистить.
Ручная очистка ядра от нерелевантных запросов
Нерелевантные запросы — это те, что не соответствуют тематике сайта. Например, чайной лавке из Тюмени не подойдут для продвижения такие запросы как «песня зеленый чай», «духи зеленый чай», «чайный гриб», «кафе кофе», «чай википедия» и т. д. В этом списке также могут быть фразы с указанием города, где нет представительства магазина, названия конкурирующих компаний.
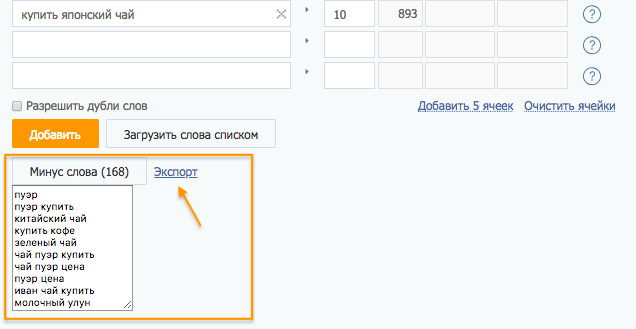
Чтобы они заведомо не попали в список, при парсинге нужно указывать возможные минус-слова. В данном случае к ним относятся «песня», «духи», «гриб», «кафе», «википедия», «спб», «москва» и т. д.
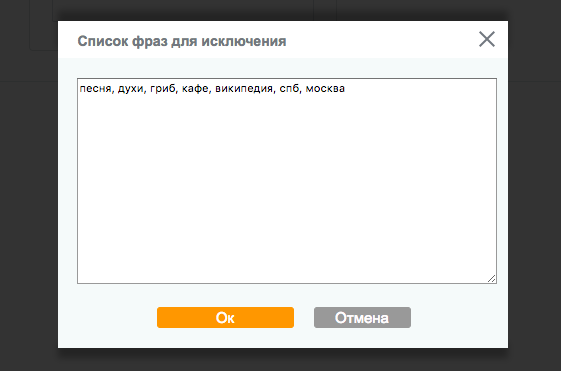
Предусмотреть все минус-слова невозможно, поэтому после каждой операции по расширению ядра нужно визуально проверять список на наличие нерелевантных запросов и удалять их.
Обращайте внимание на фразы с неуточненным интентом и исключайте их из ядра. Например, ключевые слова «золотые брови», «красный халат» (такие сорта чая) применимы также к другим тематикам — продажа косметики, продажа текстиля. Дальнейшее расширение этих фраз спровоцирует появление множества запросов, не имеющих ничего общего с тематикой чая.
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Кроме нерелевантных фраз в списке неминуемо будут присутствовать повторяющиеся фразы и лишние символы. Это мусор, который провоцирует беспорядок в файле и требует удаления.
Опытные пользователи Excel убирают ненужные строки, символы и пробелы с помощью макросов, автозамен и формул. Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Основные возможности инструмента:
удаление дубликатов в точном вхождении;
удаление дубликатов с перестановкой слов и учетом морфологии;
удаление спецсимволов в начале и конце слова;
удаление лишних пробелов между словами, в начале и конце строки;
удаление табуляции в начале и конце строки;
удаление пустых строк;
преобразование слов в нижний регистр;
замена ё на е.
Особенности сервиса:
бесплатное использование;
неограниченное количество запросов при проверке за один раз;
работа онлайн — не требует установки софта;
работа в фоне — не нужно держать страницу открытой;
не требует разгадывания капчи;
быстрая скорость обработки данных в облаке;
результат обработки можно скачать в формате XLSX;
бессрочное хранение выполненных задач в аккаунте PromoPult.
Как чистить ядро с помощью «Нормализатора слов»
Зарегистрируйтесь или авторизуйтесь в системе PromoPult — так все отчеты сохранятся в вашем личном кабинете.
Перейдите на страницу инструмента, нажмите «Добавить задачу» и укажите список запросов, который нужно почистить.
Загрузить запросы можно с помощью файла Excel (собираются данные с первого листа файла) или добавлением списка в окно сервиса (каждый запрос с новой строки).

Обратите внимание, что при загрузке XLSX-файла система считывает данные по принципу «одна ячейка — один запрос», поэтому добавляйте в файл только перечень запросов без другой служебной информации.
Далее необходимо поставить галочки — выбрать действия с ядром.
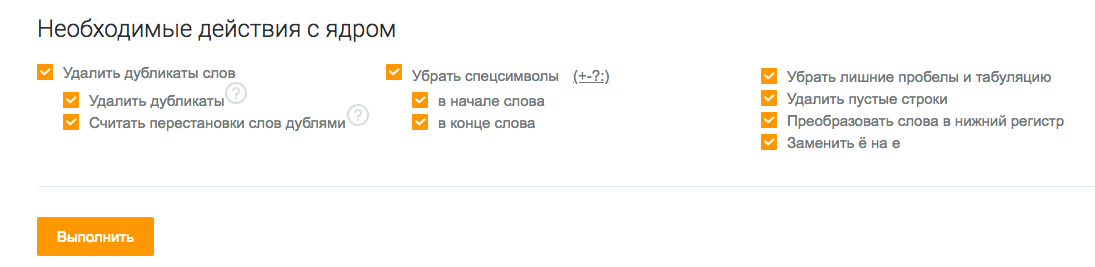
Удалить дубликаты слов
Система может удалить полностью идентичные строки (дубли словосочетаний) или строки, где слова в словосочетании имеют другой порядок и используются в других словоформах. Например, «виды китайского чая» и «китайский чай виды» будут считаться идентичными — в списке останется только тот запрос, что стоит выше.
Убрать спецсимволы
Иногда запросы для SEO могут мигрировать из контекстных рекламных кампаний и заимствовать спецсимволы. Или же попросту пользователи ставят при наборе запроса знаки препинания, которые вместе с фразами попадают в базы. Парсер поможет убрать их все одним кликом. По умолчанию заданы символы +-?: и при необходимости их можно дополнить.
Убрать лишние пробелы и табуляцию
При наличии лишних пробелов в начале текстовой строки, между словами во фразе и в конце строки система их обнаружит и удалит. Аналогично и с табуляцией — пустое пространство будет удалено в начале и в конце строки.
Удалить пустые строки
Строки без текста будут удалены.
Преобразовать слова в нижний регистр
Опция может быть полезна, когда список содержит спарсенные заголовки — часто слова в них бывают прописаны в верхнем регистре.
Заменить ё на е
На каждой площадке своя редполитика и свои правила написаний слов с буквой ё. Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Можно выставить сразу все галочки или только те, которые отвечают конкретной задаче. Ведь парсер полезен не только для чистки семантического ядра — он удобен для наведения порядка в любых списках.
По факту выполнения задачи будет доступен файл для скачивания. Задаче можно дать свое название, чтобы в будущем ее было проще идентифицировать.

В загруженном файле заполнен один лист с финальным списком запросов.
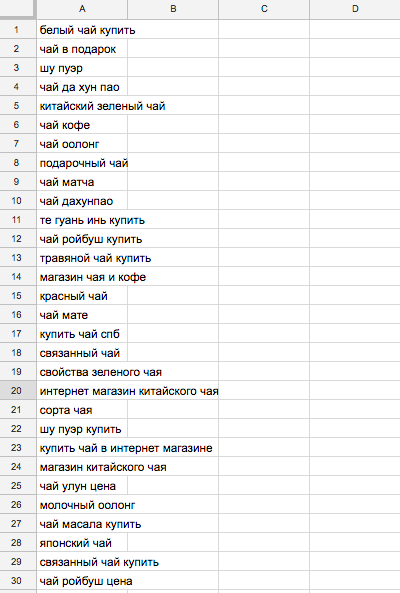
В нашем примере исходный список из 1103 запросов был обработан за 10 секунд. После чистки был удален мусор — дубликаты, занимающие порядка 11% ядра.
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Отсеяв мусор и дубли, необходимо также почистить ядро от запросов, частотность которых стремится к нулю. Они не способны генерировать трафик, поэтому нет смысла тратить время и деньги на создание и оптимизацию посадочных страниц.
Собрать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Подробный обзор работы с парсером Wordstat вы найдете в статье «Как быстро уточнить частотность запросов в Wordstat».
Убирайте мусор вовремя
Если раньше было достаточно оптимизировать сайт под сотню базовых запросов, то сегодня требуются тысячи НЧ и длиннохвостых запросов, которые вручную собрать невозможно. Благодаря парсерам эта задача решается быстро и просто, однако побочным эффектом выступает огромное наличие мусора.
Техническая чистка ядра — необходимая процедура, позволяющая исключить неэффективные для продвижения слова. Сделать проверку быстрой и точной можно с помощью инструментов PromoPult. «Нормализатор слов» доступен бесплатно. Парсер Wordstat — от двух копеек за сбор частотностей для одного запроса. Первые 50 проверок — бесплатно.
Популярные новости
30 мая 2025, 10:29
29 мая 2025, 12:51
28 мая 2025, 17:55
28 мая 2025, 10:41