Что читает ваш ИИ-ассистент: как качество базы знаний влияет на работу искусственного интеллекта
Почему нейросетка галлюцинирует и фантазирует? Дело в базе данных.
Генеративный ИИ обещает бизнесу революцию: повышение скорости анализа документов и информации, автоматизацию рутинных и частично креативных задач по созданию контента, ускорение и улучшение качества клиентского обслуживания. Но первоначальное воодушевление от впечатляющих возможностей часто сменяется разочарованием, когда ИИ начинает выдавать нерелевантные ответы, «галлюцинировать» или вовсе выдавать некорректную информацию.
Как считает Дмитрий Лактионов, директор по развитию платформы L2U InKnowledge, ключевая причина кроется не в «глупости» алгоритмов ИИ, а в «пище», которую они потребляют — информации в источнике для построения ответов, например, в базе знаний (БЗ). ИИ — несомненно мощный инструмент, но его интеллект и надёжность напрямую зависят от качества этой основы.
Как работает генеративный ИИ
Чтобы понять критическую важность БЗ, нужно разобраться в технологиях, стоящих за современным генеративным ИИ: LLM (Large Language Model — большая языковая модель) и RAG (Retrieval-Augmented Generation — поиск с дополненной генерацией).
LLM обучены на огромных массивах информации. Модели умеют генерировать связные, человекообразные ответы, понимать контекст и семантику. Однако знания LLM ограничены данными, на которых модель была обучена, и потому могут быстро устареть, если их не обновлять.
Но постоянно обучать LLM — для бизнеса очень затратно. Нужна целая команда дорогостоящих и редких специалистов: ML-инженеры и архитекторы, аналитики данных, AI-тренеры.
И здесь на помощью приходит подход RAG, который заключается в поиске и извлечении информации из выделенных источников данных (база знаний, файловые хранилища или даже интернет) и последующей генерации ответов с помощью языковых моделей.
Как это работает.
Пользователь сообщает свой запрос ИИ: это может быть вопрос, на который нужно получить короткий и чёткий ответ, просьба изучить несколько документов по теме и подготовить саммари, или задача по генерации нового контента на основании имеющихся данных.
RAG анализирует запрос и ищет наиболее релевантные фрагменты информации в подключённых источниках данных (в идеале — в вашей корпоративной Базе Знаний).
Найденные данные вместе с самим запросом RAG передаёт в LLM.
LLM генерирует ответ, опираясь на предоставленный RAG контекст.
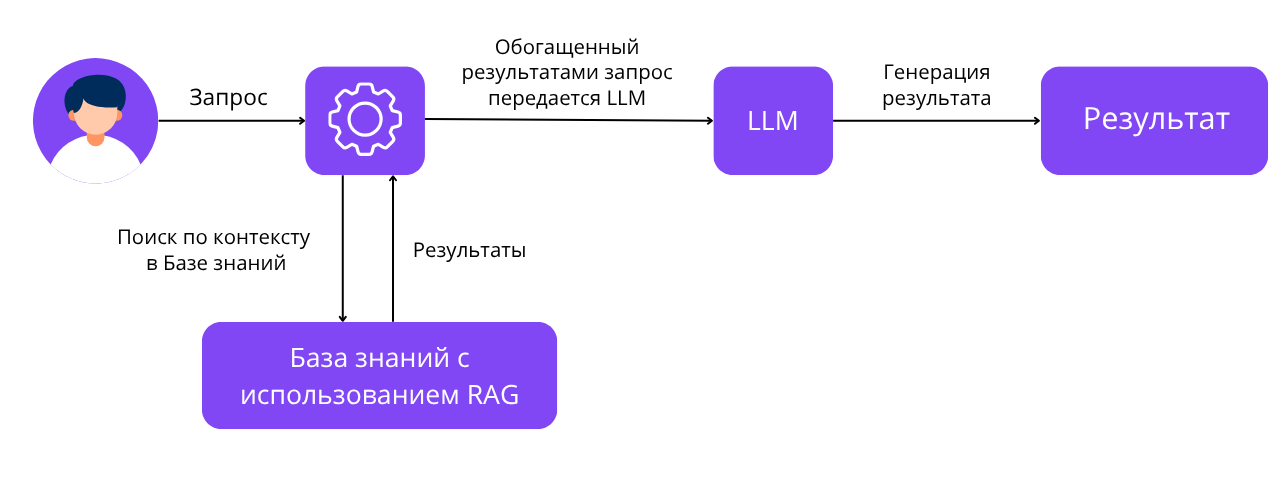
Схема работы LLM + RAG
Со стороны решение кажется идеальным: развернув систему на базе LLM + RAG, подключив источники данных и интегрировав вывод в удобный интерфейс, можно ожидать мгновенного результата.
Однако реальное внедрение в бизнес-процессы выявляет целый ряд проблем, которые касаются фундаментального вопроса — качества и происхождения данных, которые использует RAG.
Почему База знаний должна быть не просто хранилищем, а фундаментом вашего ИИ
Сама технология RAG обладает ключевыми ограничениями.
-
Не контролирует объём данных. Механизм отбора контента для генерации ответа основан на семантической «похожести» на запрос. При этом RAG не поймёт, когда информации для полноценного ответа недостаточно или когда её слишком много.
-
Не верифицирует актуальность. Система не различает свежие данные и устаревшие, рискуя передать в LLM недействительную информацию.
-
Провоцирует «галлюцинации». Чем больше неструктурированных данных из разных областей попадает в обработку LLM, тем выше вероятность некорректных выводов. Нерелевантный документ, ошибочно включённый в выборку, искажает весь ответ.
-
Не учитывает права доступа автора вопроса к конкретным документам, которые могут использоваться для генерации ответа. Что порождает риск утечки конфиденциальной информации через ИИ-канал.
То есть, сам по себе ИИ не «понимает» текст как это делает человек и не обладает возможностью проанализировать и оценить, подходит ли найденная информация в качестве ответа на запрос. Искусственный интеллект во многом зависит от того, какую именно информацию нашёл для него RAG. И в случае плотной интеграции технологий LLM, RAG и Базы знаний, используемой в качестве источника для генерации ответов, эти ограничения можно обойти.
Выгоды от использования ИИ: автоматизация, упрощение бизнес-процессов, повышение качества клиентского обслуживания, — достигаются за счёт тесной интеграции технологий LLM, RAG и Базы знаний, и решением вопроса простого и структурированного наполнения последней исходной информацией для генерации ответов ИИ-сервисами.
Риски ИИ: прямое отражение проблем в Базе Знаний
Когда ИИ «галлюцинирует», даёт нерелевантные ответы или допускает утечки данных, виноваты чаще не алгоритмы, а фундамент, на котором они работают:
Галлюцинации. Возникают, когда RAG извлекает из плохой БЗ противоречивую, неполную или нерелевантную информацию. LLM, пытаясь сгенерировать связный ответ на основе этого «мусора», додумывает недостающее. Например, может использовать прошлогодний прайс или неактуальную инструкцию.
Нерелевантность ответов. Если БЗ — это хаотичная свалка файлов без структуры и разметки, RAG не сможет точно определить, какие данные действительно нужны. В выборку попадёт то, что RAG сочтёт связанным с пользовательским запросом.
Утечки данных и проблемы безопасности. Если RAG не учитывает разграничения прав доступа Базы знаний, ИИ может выдать конфиденциальную информацию не тому пользователю. Так данные из внутреннего регламента для сотрудников или чувствительная финансовая информация попадает в ответ клиенту или другому внешнему пользователю.
В результате непредсказуемые и неточные ответы быстро убьют доверие пользователей (сотрудников, клиентов) к системе, сводя на нет все потенциальные преимущества.
Как построить Базу Знаний, которая сделает ИИ по-настоящему умным
Качественная БЗ для ИИ — не случайность, а результат применения конкретных инженерных принципов:
Структура и глубокая разметка. Позволяет RAG быстро и точно находить именно тот кластер документов, который нужен для ответа на конкретный вопрос, исключая информационный шум. Логичная организация данных напрямую влияет на точность генерируемых ответов.
Чем чётче выделены смысловые блоки, тем точнее RAG формирует информационную подборку для генерации ответа с использованием LLM. И тем меньше вероятность что полученный ответ будет содержать неточности или галлюцинации.
Иерархия. Чёткие категории (продукты, регионы, процессы, клиентские сегменты), подкатегории.
Разметка. Тематические теги, аннотации с ключевыми терминами, метаданные (автор, дата, статус).
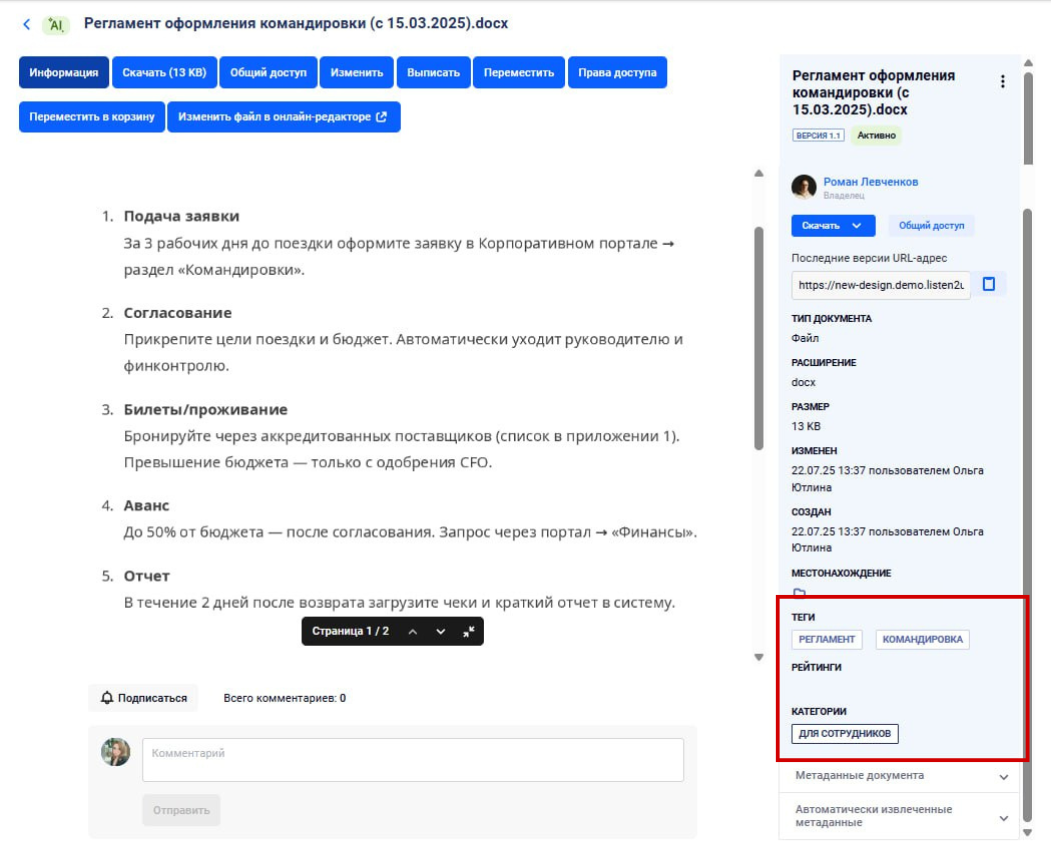
Разметка документа в Базе знаний для быстрого поиска сотрудниками и RAG на примере Базы знаний L2U InKnowledge
Актуализация, которая гарантирует достоверность ответов ИИ и обеспечивает искусственный интеллект проверенной информацией.
-
Контроль версий.
-
Автоматическая архивация: удаление или блокировка устаревших данных по расписанию или правилам.
-
Модерация/Согласование: встроенные процедуры проверки новых или измененных материалов перед публикацией.
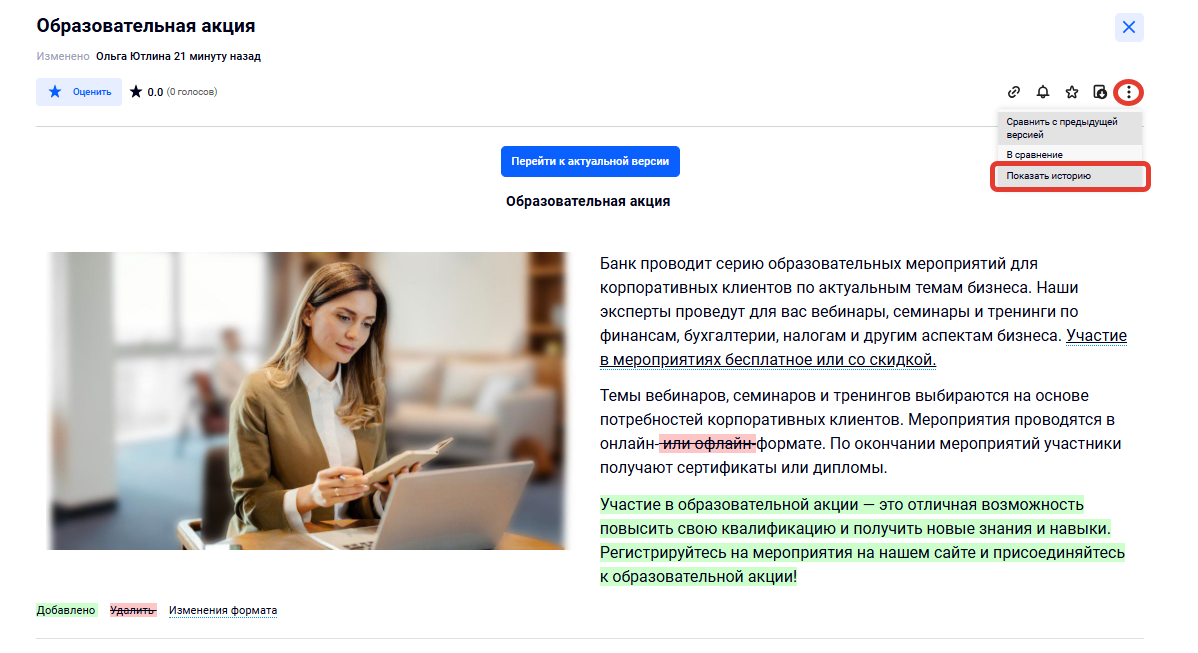
История версий на примере интерфейса Базы знаний L2U InKnowledge
Принцип единого источника истины. Сотрудники и ИИ должны ссылаться на одни и те же актуальные регламенты, условия и другие документы, чтобы исключить конфликты и противоречия.
Возможность адаптации информации для сотрудников и ИИ.
Интеграция безопасности и разграничение прав. Чтобы при формировании ответа ИИ автоматически учитывал, к каким документам конкретный пользователь имеет доступ. Клиент видит только общедоступную информацию, сотрудник — внутренние инструкции.
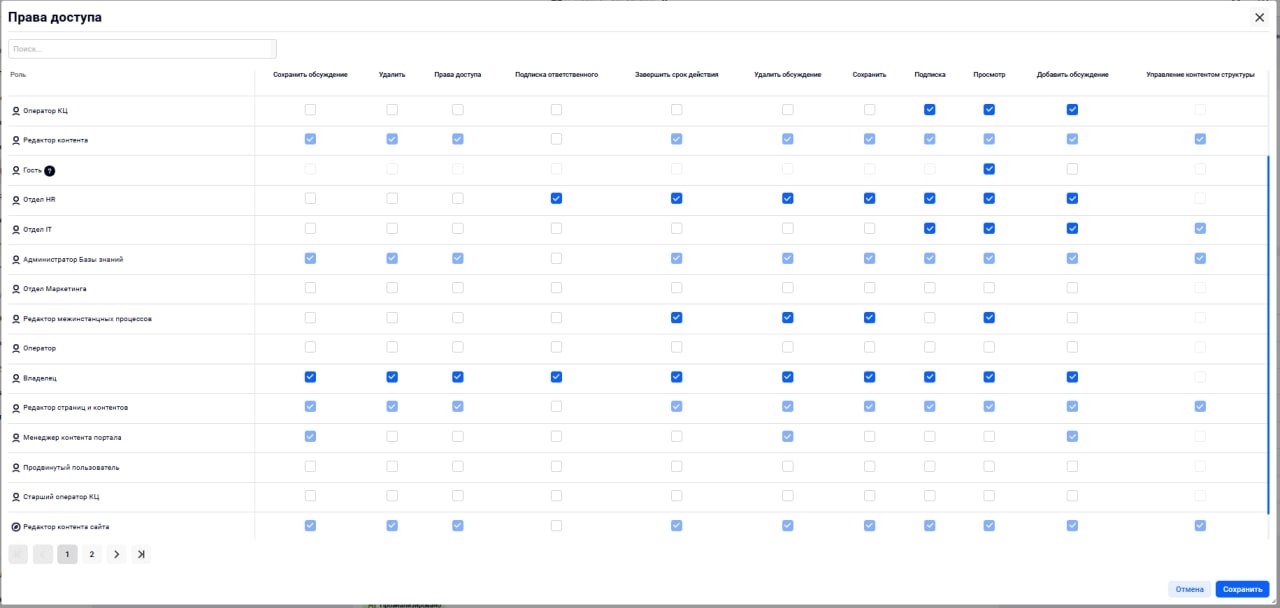
Пример ролевой модели в интерфейсе L2U InKnowledge: ограничение прав доступа и работы с документами в Базе знаний
Сужение области поиска — ключ к релевантности. RAG не должен искать информацию по всей Базе знаний, а фокусироваться на очень конкретном разделе.
Чем уже и релевантнее выборка данных, переданная в LLM, тем точнее ответ и ниже риск галлюцинаций. RAG в «чистом» виде не может определить, сколько данных нужно для ответа на конкретный вопрос, поэтому чем больше нерелевантной информации подаётся в LLM, тем выше риск галлюцинаций.
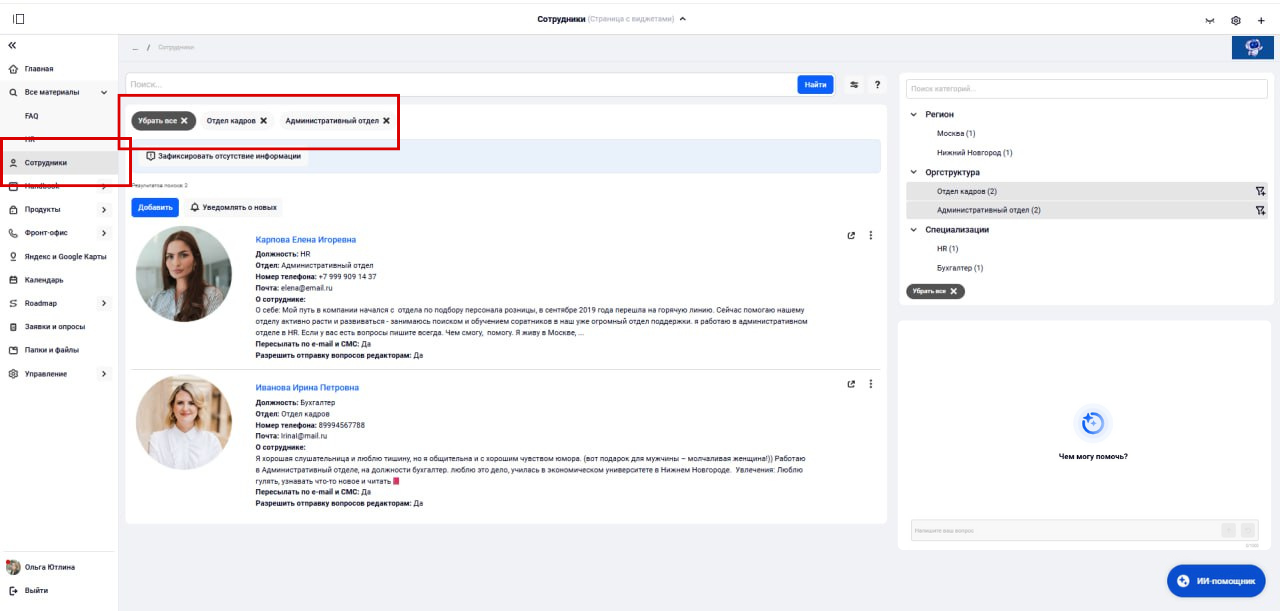
Пример сужения поиска в Базе знаний
Это достигается через структуру (поиск в конкретной категории) и интерфейсы (возможность пользователя уточнить контекст запроса или выбор системы на основе анализа запроса/прав пользователя).
Качественные промпты (Инструкции для ИИ) задают рамки генерации, улучшают релевантность и безопасность, компенсируют неточности пользовательских запросов. Не стоит ожидать, что конечные пользователи сами смогут формулировать идеальные промпты.
Нужно разрабатывать глубокие системные промпты, которые закладывают критичные для работы ИИ правила: стиль ответа, требование указывать источники, учёт политик безопасности.
Инвестиции в основу = инвестиции в результат
RAG + LLM — это не «волшебная таблетка», а продуманная система, в которой База знаний — краеугольный камень».
Поэтому мощь и надёжность вашего ИИ-ассистента — это прямое отражение качества базы знаний, которую он использует.
При этом развитие Базы знаний под особенности применения ИИ автоматически повысит качество платформы и для обычных сотрудников. Кроме того, инвестируя в качественную основу для искусственного интеллекта бизнес получает контроль над моделью и свободу выбора: если на рынке появляется более умная и продвинутая модель, ничего не стоит просто переключиться на неё, а корпус данных, на которых она работает, останется прежним.
В случае если вы задумываетесь о применении генеративного искусственного интеллекта, воспринимайте работу с Базой знаний как стратегический актив, который во многом определит успех ваших ИИ-инициатив.
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на 42@cossa.ru. А наши требования к ним — вот тут.
Популярные новости
24 октября 2025, 13:00
23 октября 2025, 10:09
22 октября 2025, 13:40
22 октября 2025, 12:41