Как и зачем мы используем передовую лингвистическую технологию NER в системе Brand Analytics
Модуль автоматического определения именованных сущностей автоматически выявляет объекты информационного поля – персоны, компании, геообъекты и предлагает удобную визуализацию структуры инфополя

Человечество производит все больше информации – как известно, за последние годы мы создали её больше, чем за всю предыдущую историю своего существования. При этом до 90% новых данных — так называемые неструктурированные данные или, проще говоря, текст. И если со структурированными данными IT-технологии достаточно успешно справляются даже тогда, когда это Big Data, то с неструктурированными данными мы научились работать куда как менее успешно.
А ведь именно они обладают большим предсказательным потенциалом по сравнению с табличными данными, с фактами, которые уже остались в прошлом. Мнения потребителей и граждан, которые по большей части агрегируются в соцмедиа, содержат в себе еще не сформулированные ощущения, идеи, смыслы и инсайты, которые только ждут своего осмысления. Для работы с такими данными на первый план выходят современные лингвистические технологии.
Для пользователей Brand Analytics доступен расширенный набор отчетов, включающий в себя интерактивные автоматические отчеты по выявленным объектам внимания—персонам, компаниям и геообъектам. В зависимости от настроек мониторинга эти объекты могут иметь отношение как к вашей компании, так и к компаниям конкурентам или к интересующему вас сегменту рынка.Отвечает за этот функционал так называемый модуль автоматического определения именованных сущностей (NER – Named Entity Recognition).
Он не только помогает мгновенно разглядеть структуру информационного потока, потребительского интереса или негативной волны, но и может стать незаменимым аналитическим инструментом для брендов, ставших на путь ситуационного маркетинга и изголодавшихся по алгоритмам выявления зарождающихся трендов.
Мы расспросили о возможностях NER руководителя нашей команды лингвистов Алексея Соловьева.
– В чем преимущество алгоритма NER перед существующими аналогами?
Прежде всего, этот модуль не использует словари или тезаурусы имен собственных и не обращается к внешним ресурсам (базам знаний). Для корректного обнаружения типа сущности достаточно контекста и графематических характеристик слова (наличие заглавных букв, цифр, тире, кавычек и пр.). На основании такой информации система принимает решение с точностью не менее 86-94% (зависит от класса сущностей).
– А почему не 100%?
Потому что 100% не бывает. Даже системы на словарях дают точность около 85%.
– Небольшая разница. Тогда зачем это надо?
А дело в том, что если словарь слов нарицательных растет в экспоненциальной зависимости и наиболее частотные слова можно учесть в словаре, то рост имен собственных близок к линейному. А это значит, что новые имена и названия появляются каждый день, и даже если попытаться учесть их, то это будет вторичная информация для системы. Наш модуль может сразу правильно типизировать имена собственные, притом что они никогда не встречались ранее.
– И неужели не путает типы, раз нет ни баз знаний, ни словарей?
Иногда путает, особенно если неправильно написано (например, вдруг автор решил написать заглавными буквами несколько слов, например, «РУЛОН ОБОЕВ» – чем не имя?). Но, в отличие от словарных систем, наш модуль может определить сущности, тип которых не всегда однозначен и меняется в зависимости от контекста.
Например.
"В Москве состоялись финальные поединки теннисного турнира «Кубок Кремля»".
«Кремль» здесь не география и даже не юрлицо, а часть составной событийной сущности «Кубок Кремля».
Или:
"КамАЗ, которым управлял 23-летний Армен Берберян, протаранил детскую автоколонну".
«КамАЗ» в данном случае — это не название компании, а название продукта.
– Какой алгоритм используется в NER?
Для определения типа сущности мы используем алгоритм так называемых условных Марковских полей. Его суть в параметризации каждого элемента лексического множества и построении фактор-графа этого параметрического пространства.
Подробнее об алгоритме условных Марковских полей читайте здесь.
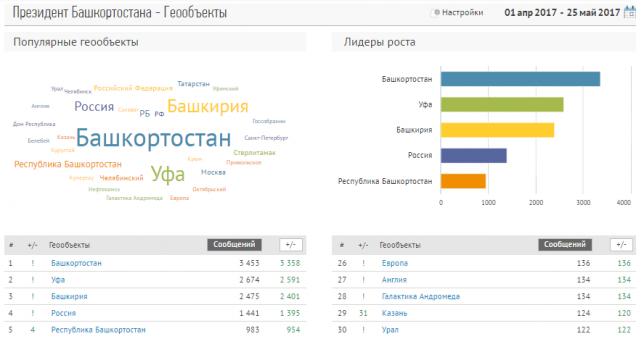
Интерфейс интерактивного отчета «Геообъекты»
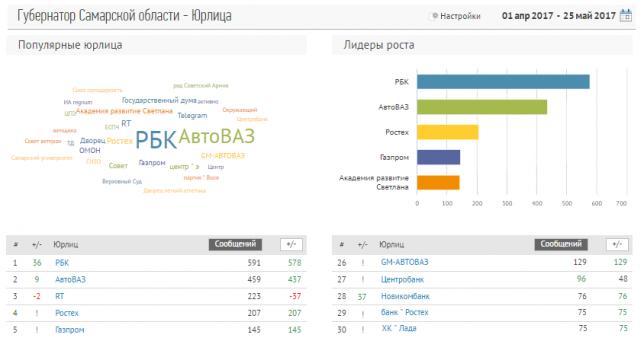
Интерфейс интерактивного отчета «Юрлица»
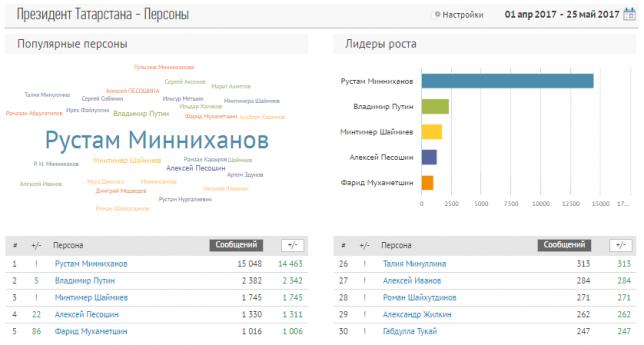
Интерфейс интерактивного отчета «Персоны»
В каждом из отчетов Brand Analytics — "Персоны", "Компании", "Геообъекты" — вам будет доступно облако объектов, гистограмма с лидерами роста и, собственно, рейтинг самих объектов с абсолютными значениями упоминаемости и приростом относительно предыдущего периода. Все данные и графики доступны как в интерактивном виде, так и в выгружаемом отчете. Что особенно важно, мы предлагаем пользовательский инструментарий для самостоятельной корректировки списка наблюдаемых объектов – объекты можно исключать из наблюдения или объединять несколько объектов в единый объект.
Заметим на полях, что спрос на подобный инструментарий возник не сегодня, но именно сегодня бренды рассматривают такие инструменты как свой приоритет. И если ранее для правильно сложенных текстов СМИ подобные технологии у нас уже работали, то сейчас, когда надо анализировать миллионы пользовательских сообщений на неграмотном русском языке, требуются новые решения.