
Рэнд Фишкин, SparkToro: что такое Inferred Links и почему предполагаемые ссылки в скором будущем должны заменить обычные
Если вы ищете значимые, достоверные индикаторы беспристрастной рекомендации, то именно предполагаемые ссылки работают лучше всего. И сегодня у Google есть возможность их правильно интерпретировать.

В течение 25 лет при ранжировании веб-страниц Google опирался на ссылки. Но сегодня, я думаю, большинство маркетологов переоценивают их важность. Есть веские доказательства того, что в долгосрочной перспективе ссылки не будут иметь столь решающего значения для рейтинга Google и заменятся лексическими ссылками, которые связывают темы и ключевые слова с брендом, веб-сайтом или страницей — то, что я называю «предполагаемыми ссылками» или Inferred Links.

Когда Google сканирует обычную ссылку, то может перейти по ней на целевую веб-страницу. Это полезно для расширения информационной базы и исторически часто было признаком некоего одобрения. Но сегодня в 80–90% случаев ссылка в интернете на товар, который можно купить, указывает на предвзятую мотивацию.
Сравните это с предполагаемой ссылкой на Pendleton’s Westerley на картинке выше. Для человека, просматривающего веб-страницы, предполагаемая ссылка менее удобна (нужно зайти в Google и выполнить поиск, чтобы найти этот кардиган), но почти наверняка является более достоверной и ценной.
Само создание ссылки, в отличие от простого упоминания в тексте, требует специальных усилий. И если текст, особенно в веб-масштабе, просто отражает мысли людей, то прямые ссылки обычно слишком мотивированны и как будто чего-то хотят от того, кто их видит. По иронии судьбы, самые беспристрастные рекомендации кардиганов, которые привели покупателей на веб-сайт Pendleton’s Westerley, вряд ли размещались в виде ссылок на Reddit или в модных сообществах Pinterest. Перечисленные ссылки, даже *хорошие* — созданы финансово заинтересованными людьми в публикациях, блогах, журналах, часто под влиянием PR-кампаний и требований линкбилдеров, ориентированных на SEO.
Конечно, если вам нужен быстрый и лёгкий доступ к веб-страницам, отлично подойдёт прямая ссылка. Но если вы ищете значимые, достоверные индикаторы беспристрастной рекомендации, предполагаемые ссылки работают намного лучше. Сегодня у Google есть возможность интерпретировать оба типа — предполагаемый и прямой.
Однако, когда дело доходит до SEO, 99,9% практиков всё равно предпочтут прямую ссылку предполагаемой. Это связано с тем, что прямая ссылка по-прежнему имеет бо́льшую ценность, чем предполагаемая, для повышения рейтинга в поисковой системе Google (когда кто-то просто в поиске набирает «мужской кардиган» или «Pendleton’s Westerley»). На сегодняшний день, в 2021 году, скажем, раза в 2. А ещё десять лет назад это соотношение было ближе к 20 или 50.
Двадцать лет назад предполагаемая ссылка была почти бесполезной (по крайней мере, в качестве исходных данных для ранжирования). Разумно ли предположить, что через пять лет это соотношение превратится в 1:1? Возможно ли, что это работает именно так уже сегодня?
Я не думаю, что в мире, где ранжированием управляют самообучающиеся алгоритмы, мы можем ответить на эти вопросы точно. Что мы можем сделать, так это лучше понять, почему в сложной системе машинного обучения предполагаемые ссылки почти наверняка обгонят их прямые аналоги.
Несколько слов о ссылках и рейтингах
Было время, когда рейтинги веб-страниц в Google основывались только на обратных ссылках: чем больше на них ссылалось других весомых страниц, тем сильнее рос их собственный рейтинг. Затем анализ ссылок стал более сложным — якорный текст, доверие, окружающий текст, анализ темы, прогнозирование веб-серфинга и так далее. Новые методы помогли Google опередить своих конкурентов в отношении спама и манипуляций со ссылками, но это была изнурительная, цикличная игра в кошки-мышки для команд, занимающихся качеством поиска и веб-спамом. В течение первых 15 лет существования алгоритмы Google разрабатывались группами инженеров, которые сидели за столами, анализировали результаты и решали, когда и нужно ли повышать или уменьшать важность того или иного элемента ранжирования. Вплоть до момента ухода Амита Сингала.
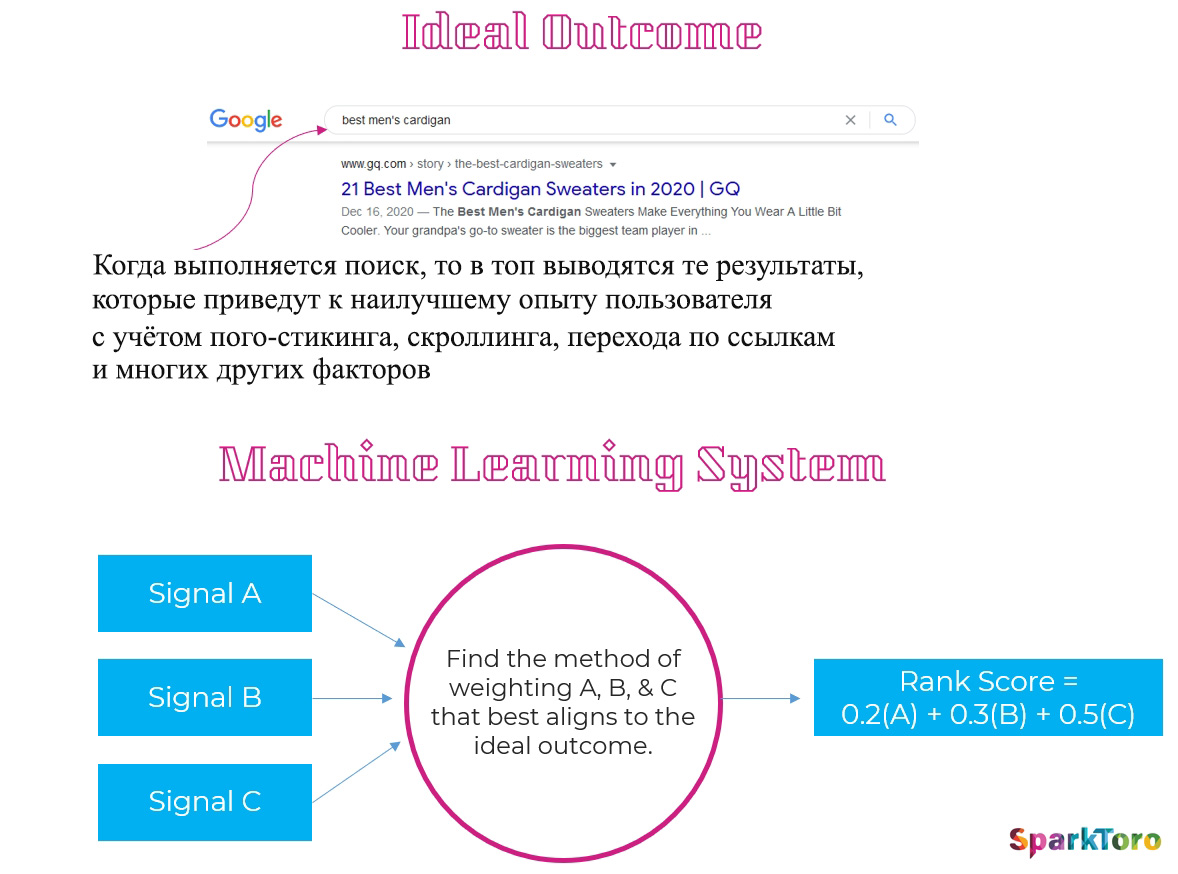
Однако сегодня Google гордится тем, что его современные рейтинги строятся с помощью алгоритмов глубокого обучения. В этой модели инженеры сообщают системам, что нужно оптимизировать (обычно это показатель удовлетворённости пользователей), а алгоритмы уже сами решают, какие элементы ранжирования использовать и как/когда их взвешивать.
Если компьютерные вычисления определят, что модель с более взвешенными связями уступает модели с более взвешенными предполагаемыми связями, система обучения автоматически изменит вес ранжирования. Предположительно, в самых передовых системах, созданных Google, алгоритм не только определяет вес, но и сами входные данные, потенциально открывая новые способы ранжирования самостоятельно.
Возможно, в 2021 году ссылки по-прежнему остаются основой системы ранжирования, и поэтому система выбора машинного обучения до сих пор отдаёт предпочтение им. И, может быть, так будет продолжаться ещё долгие годы. Но я в этом сомневаюсь.
Чем хороши предполагаемые ссылки
Красота предполагаемой рекомендации, исходящей из естественно написанного текста (в просматриваемых социальных сетях или на веб-страницах), неоспорима. Потому что это:
-
Масштаб — ведь текста в миллионы раз больше, чем ссылок.
-
Больше контекста — текст можно анализировать множеством способов, единственными реальными ограничениями являются вычислительная мощность — то, в чём Google преуспел за последнее десятилетие.
-
Дополнительная атрибуция: кто написал эту статью? где это было опубликовано? какие признаки авторитета и компетентности несут автор и издатель? Учитывая, как много ссылок добавляется постфактум (особенно в мире журналистики, блогинга и корпоративного копирования), атрибуция между писателем/издателем и между брендом/концепцией/страницей имеет огромное значение.
-
Выше достоверность — как упоминалось выше, ссылки лишь иногда постятся по доброте душевной. Гораздо чаще за созданием или изменением ссылки стоит финансовая мотивация или знания в области SEO. Это же возможно провернуть и с текстом, но всё-таки в гораздо меньшем масштабе.
В прошлом не хватало сложного, детального анализа, необходимого для того, чтобы предполагаемая ссылка превосходила по весу прямую. Уже сегодня для этого есть все возможности. А в будущем они станут ещё лучше, дешевле и быстрее.
Даже если сегодня правят балл ссылки, я не вижу причин задерживаться на этой модели надолго.
А что если?
Вчера я запостил в Твиттере предварительный обзор этой теории и получил отличные отзывы, в том числе от критиков.
Например, Шон Дауэс утверждает, что текстовые упоминания более подвержены неправильному толкованию, чем ссылки, и я согласен. Я думаю, что это одна из основных слабостей теории предполагаемых ссылок и текстовых связей в целом. Но я думаю, эту проблему можно решить за счёт накопления большего количества данных и совершенствования систем анализа текста — это именно те области, в которые Google любит вкладывать средства, и которые дают ему конкурентное преимущество.
Кроме того, я думаю, что мир, в котором предполагаемые ссылки получат такой же или даже больший вес, чем прямые, никогда не станет миром, в котором ссылки вообще не считаются.
Ссылки и предполагаемые ссылки часто встречаются одновременно, и в тех случаях, когда они встречаются, можно выявить шаблоны, которые помогут Google определить, как интерпретировать контент, ссылающийся на страницу, даже если в нём вообще нет ссылки или содержится лексическая путаница.
Думаю, что Google (и множество других систем анализа текста) практически уже сейчас на той стадии, когда они могут отличить положительное высказывание от отрицательного, а одобрение — от простого упоминания. А значит могут понять, что мнение заслуживающего внимания эксперта в своей области должно иметь больший вес, чем реплики дюжины или даже сотен анонимных учёток в Twitter.
Конечно, в идеале бренды и веб-сайты хотели бы, чтобы ссылки существовали, потому что это упрощает навигацию. И всё же даже это не противоречит интересам Google — вероятнее всего, именно он является главным бенефициаром всех текстовых рекомендаций в интернете. Ведь что делают люди, когда видят упоминание о кардиганах пресловутого Пендлтона без ссылки? Правильно — идут в поиск Google :–)
Источник: Inferred Links Will Replace the Link Graph

Тест SEO 2 недели
В топ за 2 недели бесплатно. Предоплата не нужна.
Подключай тест-драйв SEO в PromoPult:
- Подберем ключевые слова.
- Выполним задачи по базовой оптимизации.
- Проставим ссылки с надежных сайтов.
- Создадим контент под информационные запросы.
Реклама. ООО «Клик.ру». ИНН 7743771327. ERID: 2W5zFG5yNWU
Популярные новости
15 июля 2025, 15:51
15 июля 2025, 15:42
15 июля 2025, 13:27
14 июля 2025, 13:09