Как AI помог находить тренды и не сжигать время на ленту новостей
Рассказываем, как мы сделали свой отраслевой дайджест новостей для официального Telegram канала и сотрудников агентства DOT при помощи AI.

Жизнь гораздо интереснее, чем бесконечное чтение отраслевых новостных лент или TG/X-каналов. Но оставаться «в повестке» надо, а также «надо знать тренды». Трендвотчинг в какой-то мере становится даже услугой, а у компаний и коллективов есть запрос на «знание стоящих трендов».
Но новости — это текст. А текст — это идеальное топливо для AI. Вот мы и решили попробовать.
Мы насчитали, что сотрудники агентства читали более 30 разных отраслевых каналов, которые выпускали более 200 постов ежесуточно. Естественно, часть этих каналов просто перепечатывали одни и те же новости.
Мы поставили себе задачу — сделать свой отраслевой дайджест. Всё самое важное за последние два дня:
- Избавиться от дублей новостей;
- Получать выжимку в удобном виде — чтобы можно было перейти на первоисточник, а также не терять доступ к вложенному/закреплённому медиаматериалу;
- Получать всё в корпоративном мессенджере либо в TG.
Без нейросетей, которые понимают контекст, сделать бы это было невозможно. Но в эпоху ChatGPT/Claude/Gemini задача оказалась более чем решаемой.
В видео ниже Андрей Мазур, директор рекламных продуктов и услуг агентства DOT, подробно рассказывает о том, как мы использовали нейросети для того, чтобы уменьшить «инфошум», но при этом следить за трендами.
Что нам надо делать
- Собирать информацию = парсер;
- Обрабатывать информацию = нейросеть;
- Получать дайджесты = произвести визуализацию (собрать текстовую выжимку/переписать, добавить медиа/иллюстрации);
- «Движок», который это все «держит и заставляет работать».
Буквально несколько лет назад решить задачу парсинга и движка, кстати, пришлось бы написанием своего ПО. Но и на эти аспекты нашлось легкое решение.
Что мы сделали
ПЛАТФОРМА
Основой нашего продукта служит N8N. Прекрасная no-code платформа, о которой «все наслышаны». Почему она? Короткий ответ — это идеальная платформа, если вам нужно «воткнуть» в неё другие сторонние сервисы. Для нашей задачи важны гибкость — возможность быстро что-то подключить/отключить/протестировать замену одного микро-сервиса другим. Кроме этого, нельзя отрицать удобство визуального конструктора.
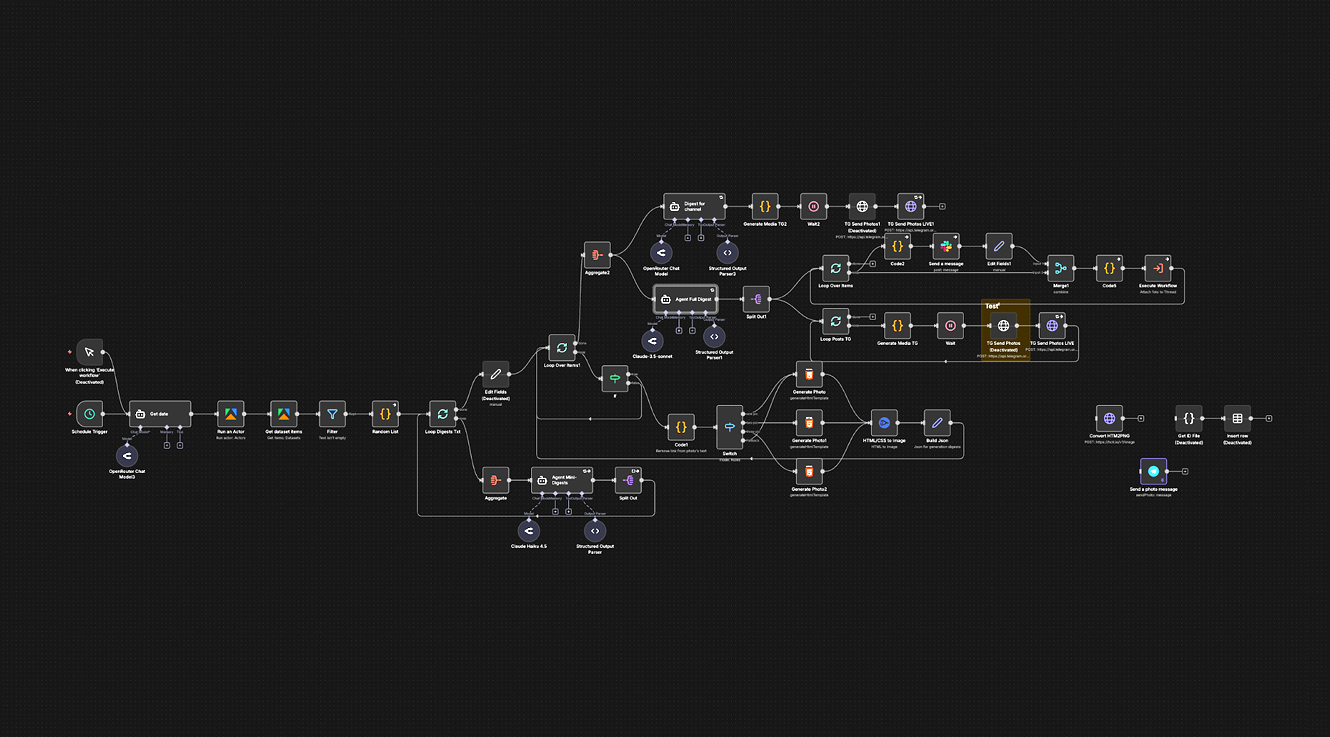
ПАРСИНГ
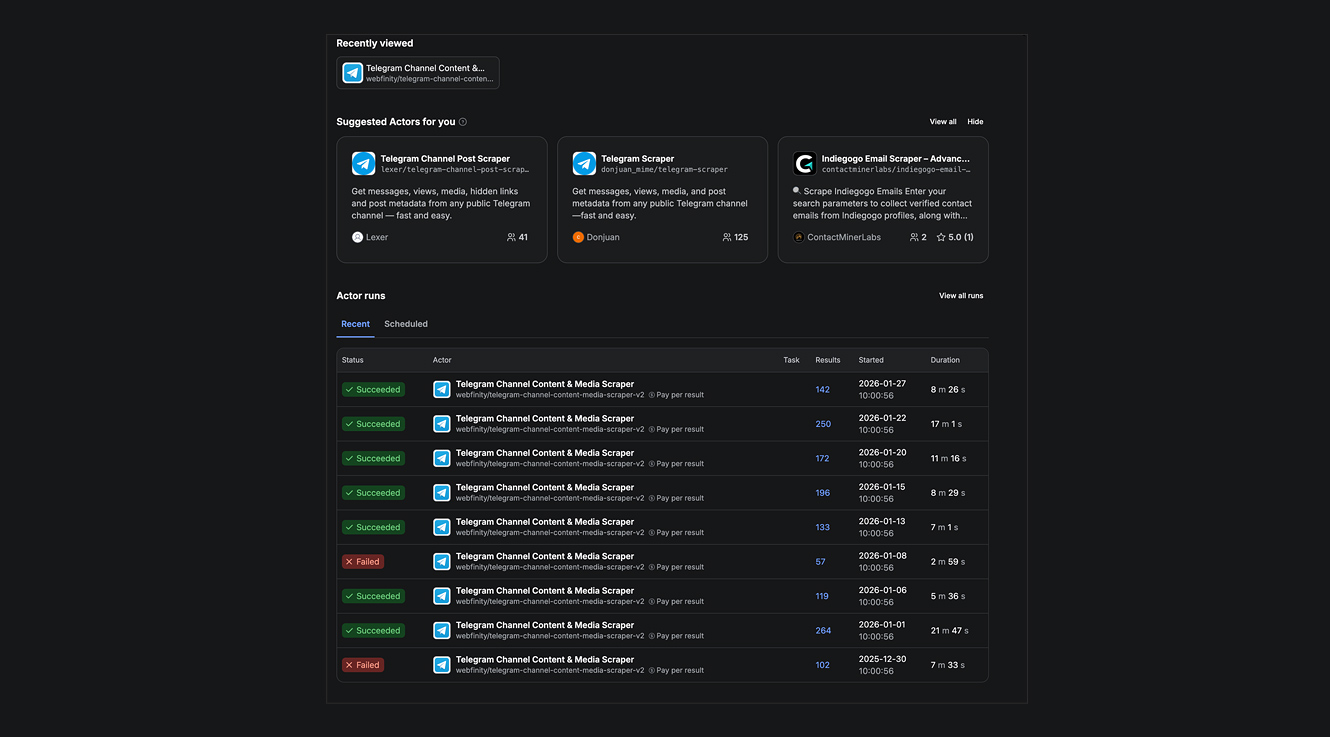
Задачу по сбору данных нам помог решить Apify. Прекрасный сервис, который продает «почасовую отработку» различных микро-сервисов. Главное, чем известна эта платформа, это множество сервисов по парсингу, которые поддерживают независимые разработчики.
Это решало «одну из главных головных болей» — как избавиться от необходимости поддерживать и обновлять парсер при каждом новом изменении от платформ. Что TG, что X постоянно модифицируют API, а также борются с «голым парсингом».
Благодаря Apify можно получать массив данных быстро и удобно. Конечно, если у вас очень много данных из TG, то дешевле будет купить платный доступ в TGStat. Но парсинг — отдельная тема. Нам нужно было быстро «собрать» наши источники и запустить свою идею.
АНАЛИЗ КОНТЕНТА
Конечно, сердцем продукта является нейронка. Весь смысл в том, чтобы «скармливать» в нейросеть контент и получать «сухую выжимку». Естественно, на старте разработки мы не знали, какая AI-модель подойдёт лучше. Поэтому для «тестирования разных мозгов в одном окне» мы использовали OpenRouter. Он позволил нам выполнить 1 подключение и практически «на лету» смотреть/менять модели. Казалось, дело в шляпе. Но есть ряд ограничений, которые нужно соблюсти, чтобы «всё сработало красиво».
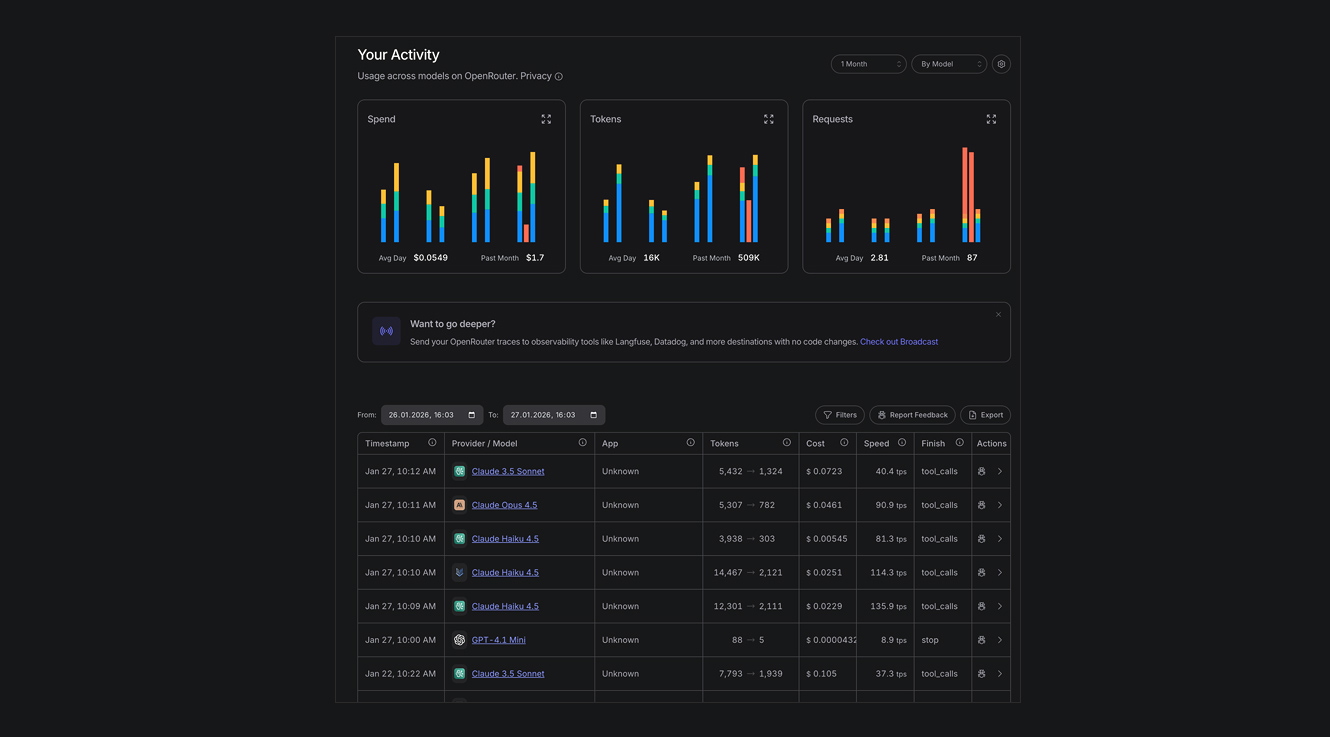
ОГРАНИЧЕНИЯ ОБЪЕМОВ АНАЛИЗИРУЕМОГО КОНТЕНТА
Во-первых, парсер выдает контент из TG каналов как последовательную выгрузку. Начал парсер с первого канала и «пошёл с утра до вечера собирать всё, что было в канале». То есть, сначала идёт канал 1, потом канал 2, потом канал 3 и т. д. Но вот незадача — «засунуть» в нейросеть сразу условные 500 постов нельзя. Есть ограничения по размеру массива, который нейронка анализирует, по крайней мере, если не переделывать всю структуру баз данных, для чего N8N слабоват. Надо разделить «нашу стопку новостей» и отправить её на анализ по частям. Верно?
СОБЛЮСТИ РАЗНООБРАЗИЕ
Не верно! Когда AI получает массив для анализа, он рассматривает только его. Он словно ездовая лошадь с шорами на глазах. В моменте нейронка не знает «что ещё следом будет блок новостей, а потом ещё один следом и т. д.» А чтобы точно составить «картину дня», нужно осознать все новости целиком. Мы же что хотим: «Почитай новости эти, те, а ещё вон те. Пойми, что «эти с теми пересекаются, и удали лишнее да и скажи мне самое важное».
Получается, что нельзя просто порезать массив на несколько равных частей. В таком случае, внутри кусков вполне могут оказаться новости, на 90% состоящие из одного крупного канала. Поэтому сначала мы применяем функцию и перемешиваем все наши новости, чтобы был равномерный «суп из всех сплетен и трендов», а уже потом режем по частям.
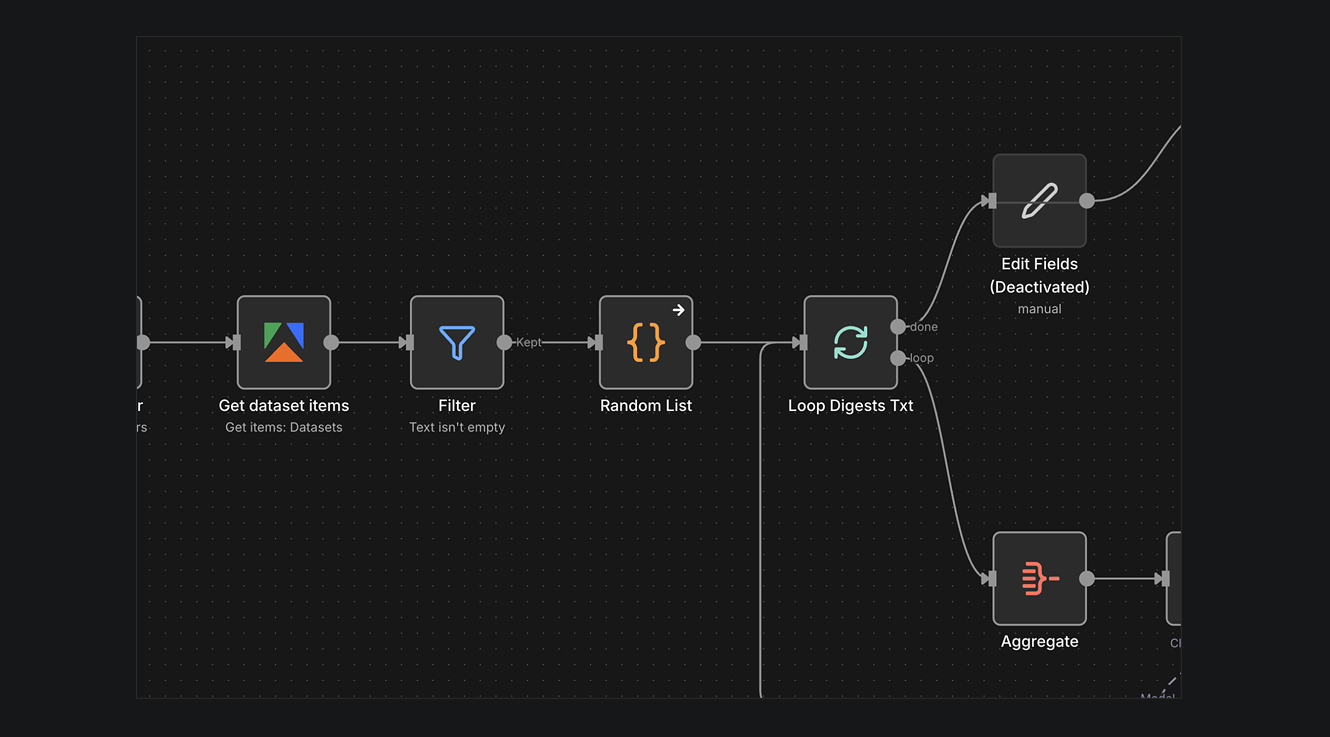
АНАЛИЗ AI-МОДЕЛЬЮ
Разрезаем наш большой массив на части и отправляем в AI-модель на анализ, чтобы посмотреть, что у нас получилось. Небольшой совет — самый простой и быстрый тест модели вы можете сделать непосредственно в интерфейсе чата через OpenRouter. Конечно, в интерфейсе N8N лучше добавлять подключение сразу к той AI-модели, которая вам понравилась.
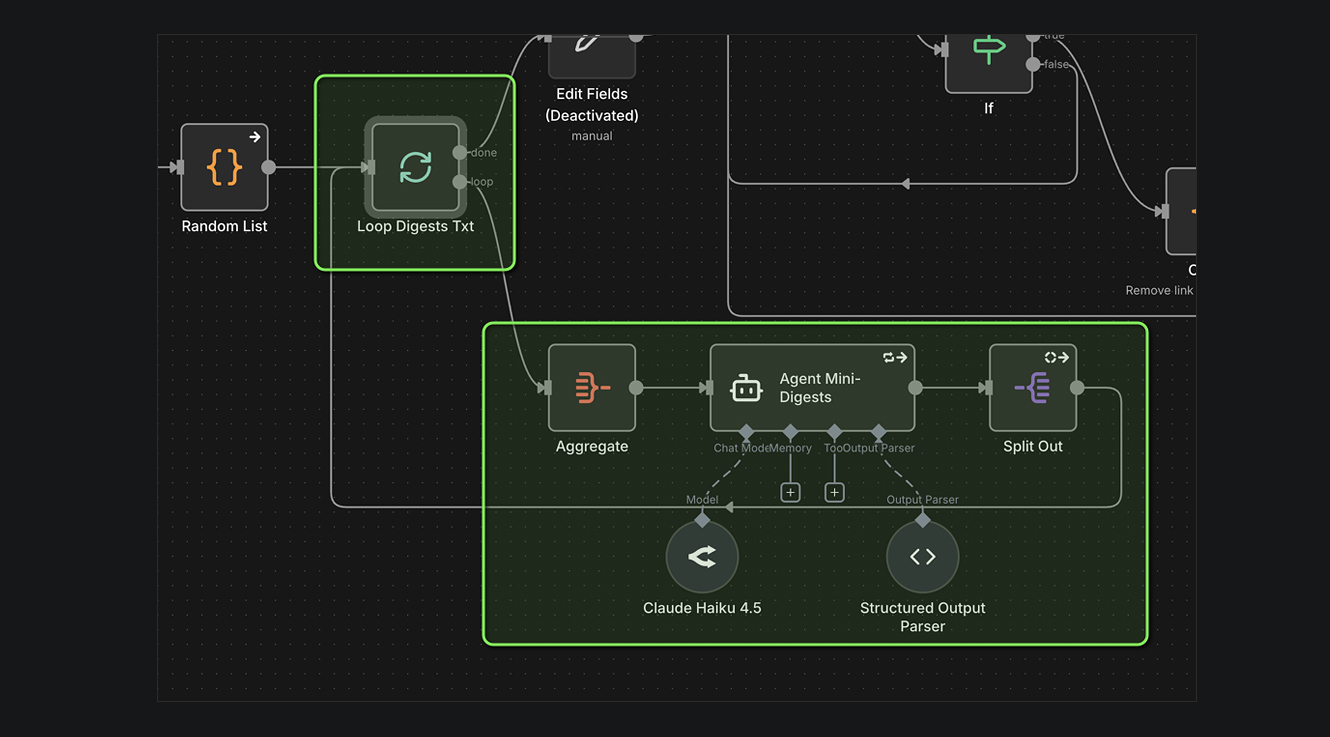
ПОДГОТОВКА ПРОМТА
Самое важное — подготовить правильный промт. Этот процесс может занять длительное время. Наш промт больше 3000 знаков. Что мы там учитываем:
1. Роль. «Ты — аналитик и редактор, делающий дайджесты по постам из Telegram-каналов. Твоя задача — составлять расширенные дайджесты в стиле медиааналитики...»;
2. Запреты. Менять и модифицировать исходные URL (!), расширения файлов (!), включать иные медиаматериалы (!) в этот массив. Последнее, чтобы AI-модель не «подмешала» своё;
3. Правила обработки информации.
- Что делать с ссылками из первоисточников. К примеру, если в составе новости ссылка на презентацию или какое-то исследование;
- Заголовок. Мы же новости анализируем. Нам сохранять заголовки или нет;
- Агрегация по темам (!). Самое важное и нужное. В нашем случае мы все новости разбиваем на 3 темы — технологии, реклама, маркетинг;
- Правила игнорирования и объединения. Просим повторяющиеся новости удалять, если новости НЕ из нужной нам категории — пропускать. Именно этот момент и делает ту самую «магию» и удаляет всё лишнее, а нужные нам тренды и новости благополучно оставляет.
4. Состав одной новости. Что именно нейронка оставляет по какой-то конкретной новости после переработки массива новостей. К примеру, оставляет заголовок, медиаматериалы, ссылки из первоисточника. Чтобы одна новостная единица выглядела: «McDonald’s выпустил розовый бургер. Фото. Ссылка»;
5. Правила форматирования. Ссылками прошиваем сам текст. Это важно для удобства прочтения внутри мессенджеров, чтобы кликабельным был сам текст сообщения;
6. Форматы изображений. Тоже важно, потому что картинки могут быть разных размеров, а также по-разному отправляться через сторонний API мессенджеров, когда мы наш готовый дайджест будем присылать пользователю;
7. Проверку готового результата. Дополнительный шаг, повышающий надежность работы модели. Проверяем, что дайджесты не пустые, что есть ссылки, есть картинки;
8. Пояснение, что делать, если анализ выдал пустой результат;
9. Выходной формат.
Повторимся, что промт = сердце продукта. Не спешите, поэкспериментируйте. Кстати, очень хороший ход — спросить у самой модели: «стоит ли что-то добавить в промт или как его модицифировать». Это известный прием, который приносит стабильные улучшения любого промта.
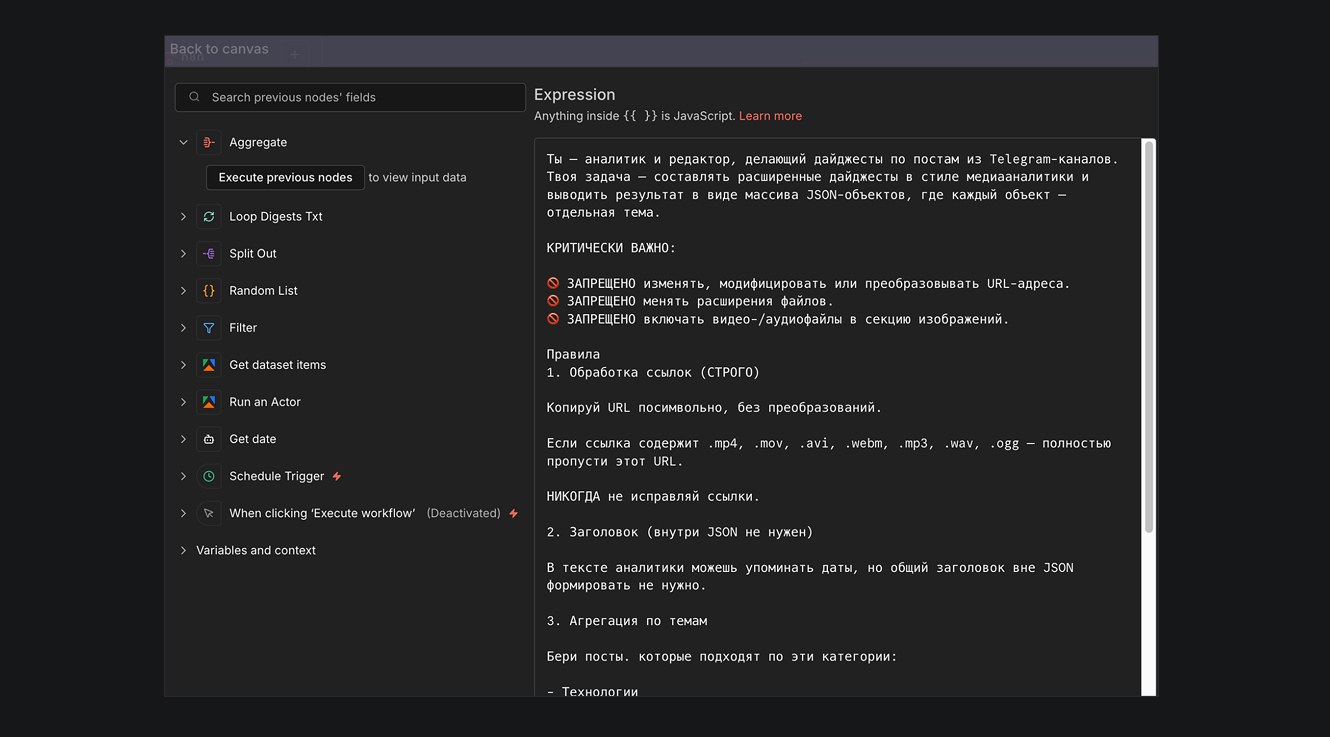
СОЗДАНИЕ КОЛЛАЖЕЙ ДЛЯ НОВОСТИ
Традиционно, дайджест — это комбинация текстовой новости и сопроводительной картинки. Часть пользователей любит не только читать текст, но и переключать картинки. Это необязательное дополнение, но мы решили его реализовать.
Путь генерации сопроводительных картинок состоял из промежуточного этапа — веб-дизайнер (но это может сделать и нейронка, если в коллективе нет дизайнера) разработала шаблон оформления.
Почему дизайнер? Потому что нам нужен HTML-код, в котором есть зона для текста и зона для 3-х изображений. Конечно, состав может меняться. Мы исходили из того, что к примеру, у вас 1 сообщение включает в себя 9 новостей. На каждую новость 1 картинка. В одной карточке размещается до 3-х изначальных картинок и короткий текст по событиям. Таким образом, в каждом дайджесте для 9 новостей нужно 3 сопроводительных изображения (3 новости по 3 картинки в 1 карточке) .
Для того, чтобы нейросети было удобно компоновать новости, мы реализовали шаблон для 1, 2 и 3 картинок. Модель сама определяет, какое количество картинок подходит для дайджеста, и добавляет их к текстовой части поста. Пример дизайна карточки и оформление готового дайджеста показали ниже.
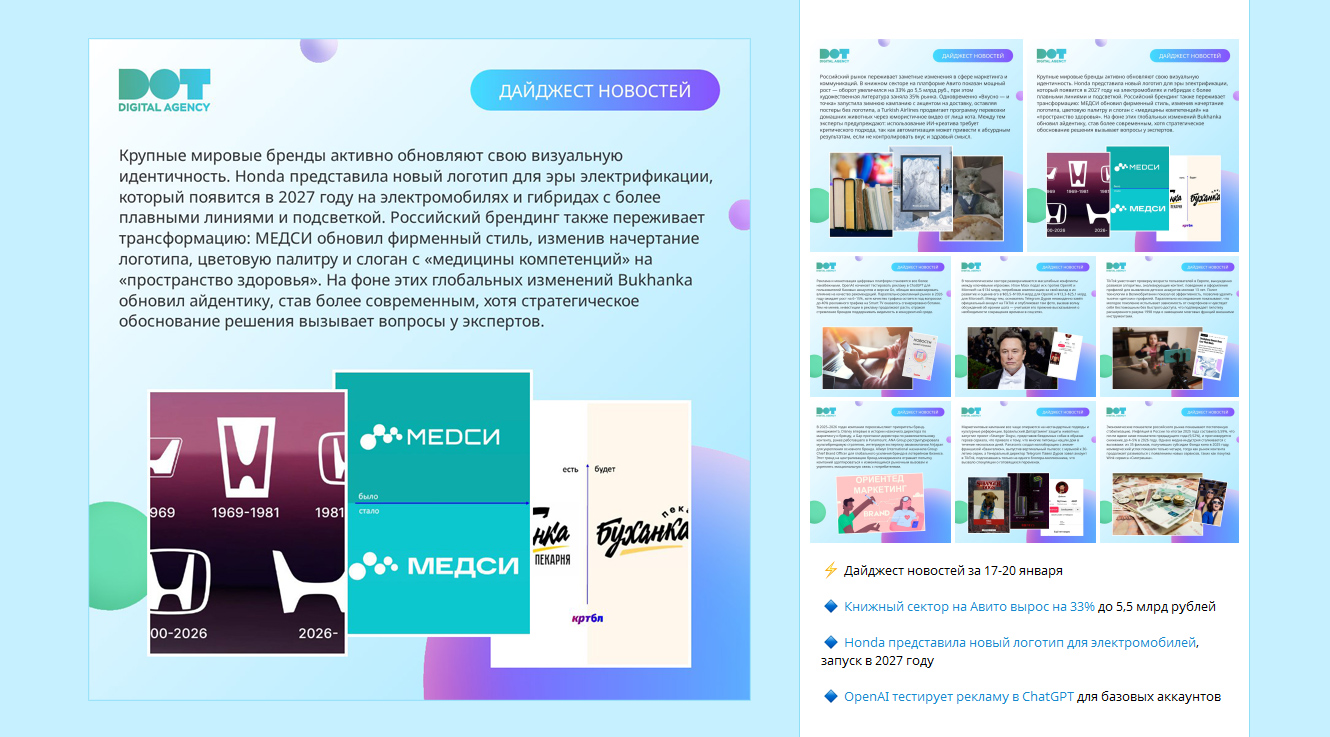
В N8N настроены шаблоны под число изображений. N8N скачивает изображение из исходной новости. Добавляет это изображение в шаблон, который сделан в HTML. А дальше мы идем в сервис HTML/CSS2IMG и превращаем «сайт в картинку». Но и, конечно, текст. На примерах выше видно, что карточка — это комбинация текста и картинки. Готовые сопроводительные карточки забираем в пост.
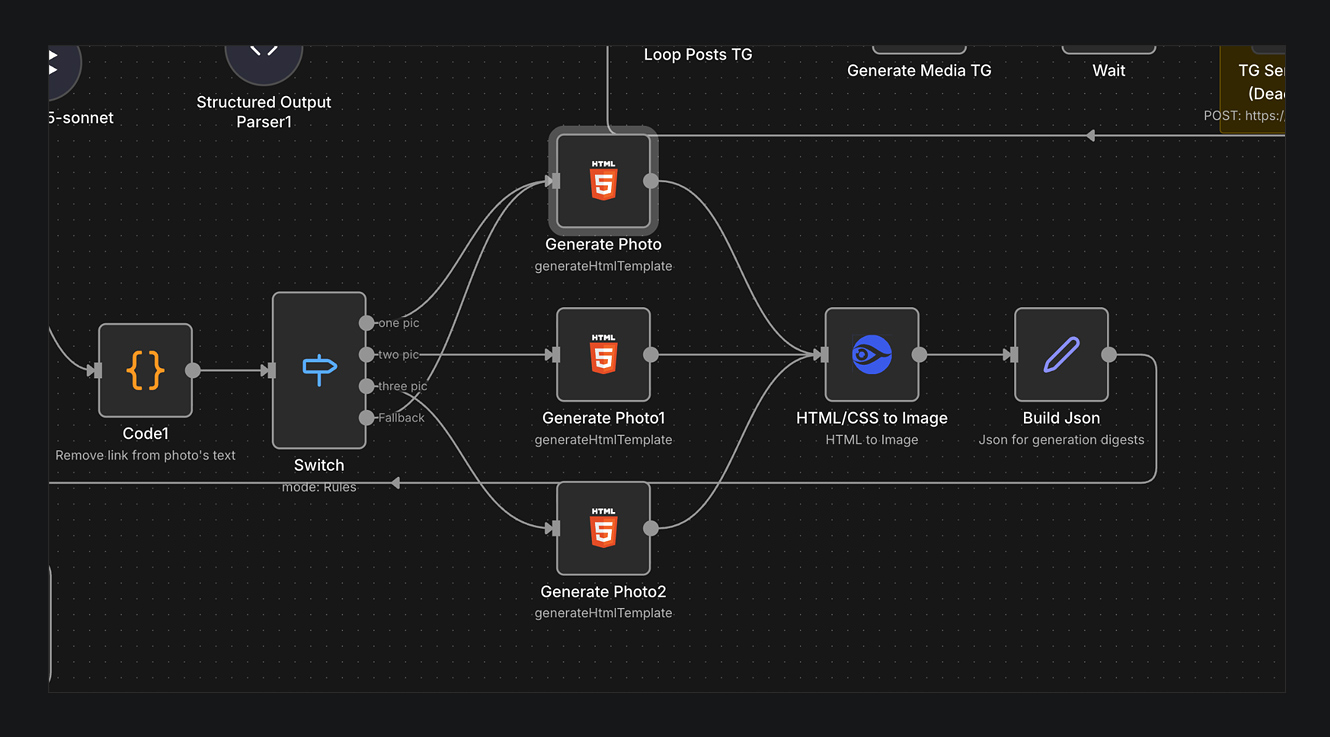
ОТПРАВКА ДАЙДЖЕСТА В МЕССЕНДЖЕРЫ
Финальный этап. На этом этапе мы повторяем наш промт с небольшими изменениями. Повторяем, потому что результаты первого анализа мы «забрали в сопроводительную картинку». Такая последовательность не обязательна. Именно из-за того, что мы делали «сопроводительные карточки/картинки», которые содержат как изображения, так и короткое описание, то мы сначала решали эту задачу.
Теперь нам надо отправить сам текст новости в избранный мессенджер.
TG:
Для отправки в TG сначала модифицировали наш промт. Указываем лимиты по длине сообщения, а также указываем, что обязательно использовать формат сообщения Markdown v2, чтобы текст был кликабельным, были видны спецсимволы и т. д.
После получения готового сообщения, то есть комбинации текста и картинок, нам нужен TG-бот.
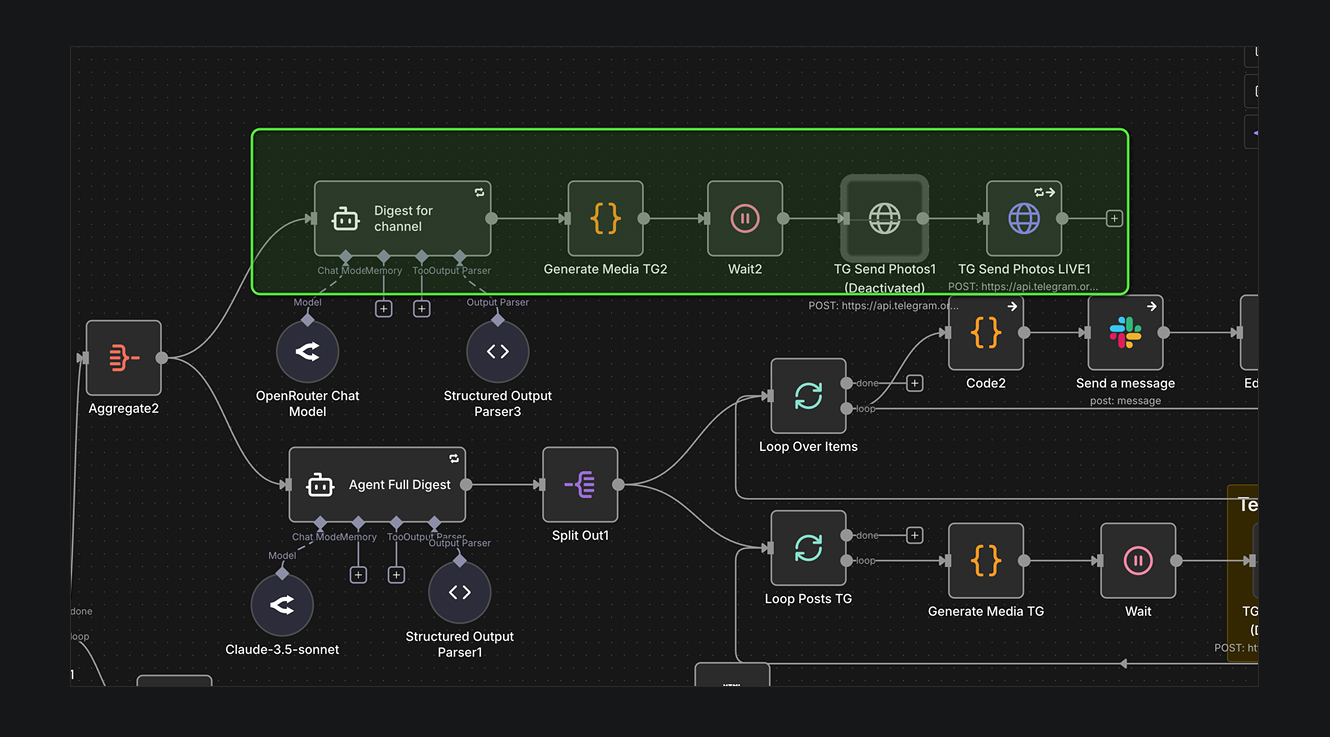
В этом материале расписывать путь создания собственного бота мы не будем, для этого нужны отдельные инструкции. Но, естественно, N8N «просто так» напрямую в TG ничего публиковать не может. Однако, создав простого пустого бота и получив ключ от API, вы спокойно можете отправлять сообщения через него в нужный вам канал или личные сообщения.
Slack:
Примерно аналогичный путь со Slack. Рекомендуем повторно пропустить массив через AI-модель, где в промте будут указаны нюансы генерации сообщения с учетом специфики требований Slack к длине сообщения, а также спецсимволам. Дальше нужно будет запустить на сервере своего Slack-бота, который будет использоваться для отправки сообщений из N8N в Slack.
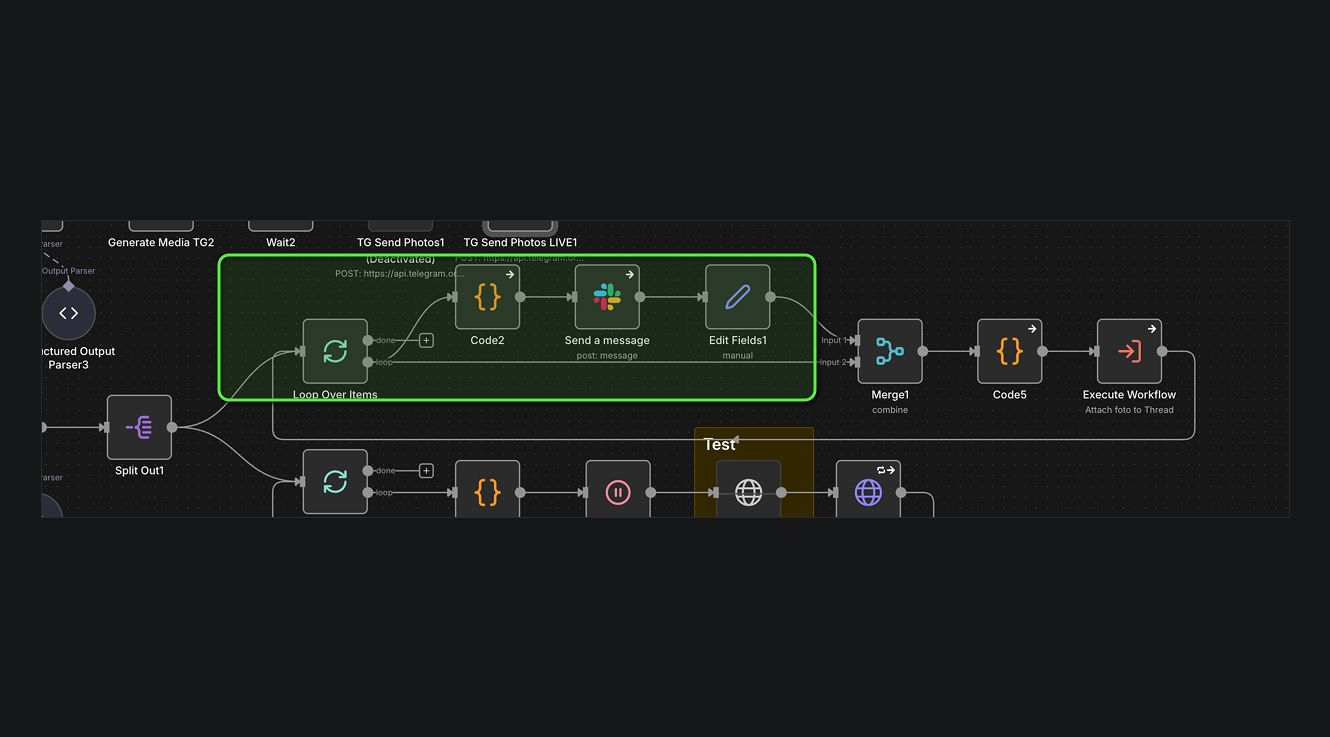
ПЕРСОНАЛЬНЫЕ ДАЙДЖЕСТЫ
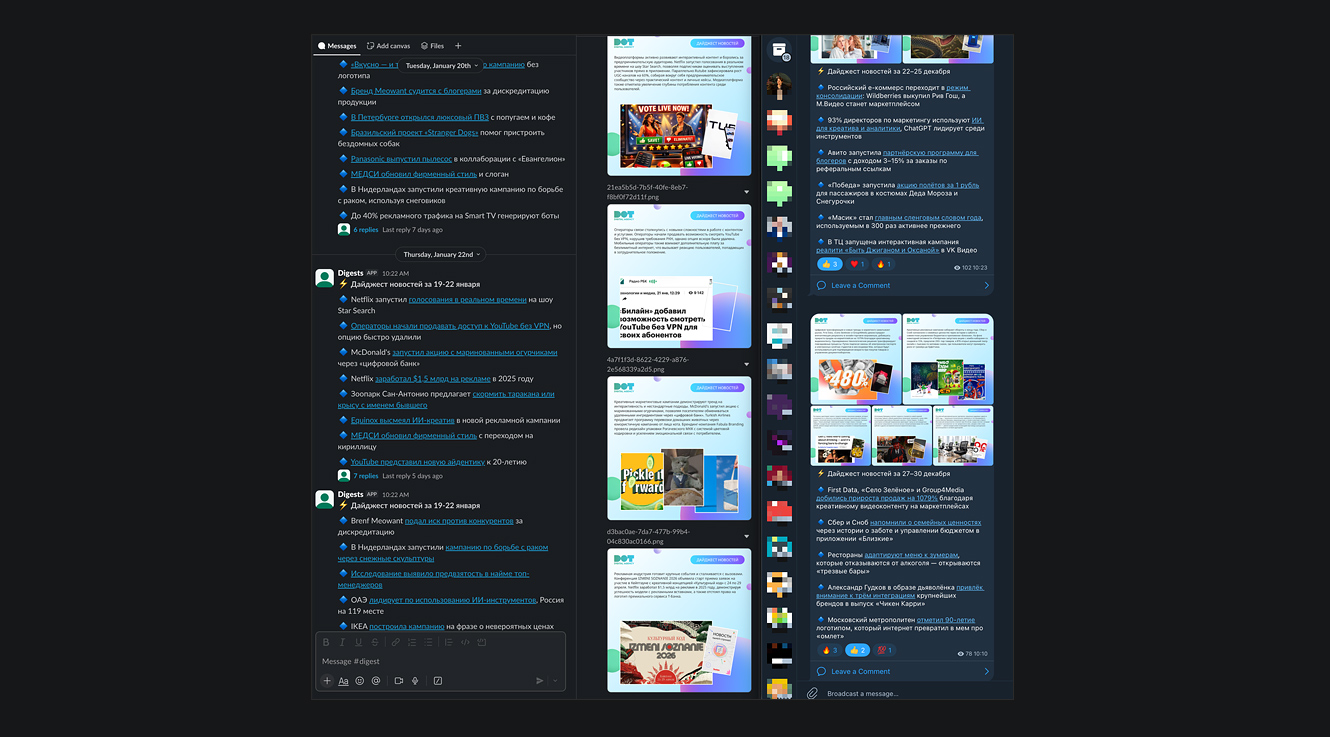
Итогом работы стали персональные новостные дайджесты, которые приходят как в корпоративный мессенджер Slack, так и в TG. Это удобно, экономит время, а также позволяет держать весь коллектив «в контексте».
Итоги и выводы
Естественно, применение AI в вашей отрасли может быть основано не только на уплотнении и персонализации новостей и защите от инфошума. Примеров и идей практического использования нейросетей для получения ключевых сводок масса:
- Недвижимость — выгрузки/выдержки парсинга сайтов объявлений;
- Торговля — изменения цен по мониторируемым товарам;
- HoReCa — открытия ресторанов, изменения цен;
- Финансы — вообще бесконечно много. От публикаций биржевых торговых стратегий до объявлений изменений финансовых условий в банках.
В двух словах, это мощный инструмент, который можно адаптировать под вашу задачу. Кстати, естественно, если у вас есть корпоративный портал и бизнес формирует определенный объем ежедневной/еженедельной отчетности, то можно «вычленять смыслы» оттуда и отправлять их руководству.
Если вам нужны внедрение Искусственного интеллекта или разработка чат-бота, обращайтесь в DOT. Пройдем вместе успешный путь от самой смелой идеи до блестящего результата!
Автор статьи — Андрей Мазур, директор рекламных продуктов и услуг агентства DOT.
Популярные новости
1 апреля 2026, 15:00
31 марта 2026, 13:10
31 марта 2026, 12:16
31 марта 2026, 11:46
31 марта 2026, 10:36